
Temporal Hallucination in AI: What It Is, Why It’s Dangerous, and How to Fix It

Your AI just told a customer that your company is “currently led by” an executive who left two years ago. Or it confidently stated that a feature you discontinued in 2023 is “still available.” Nobody flagged it. Nobody caught it. The customer read it, believed it, and made a decision based on it.
That’s not a small error. That’s temporal hallucination — and it’s one of the most underestimated risks in enterprise AI deployment today.
Let’s be honest: most conversations about AI hallucination focus on made-up facts or fabricated citations. But temporal hallucination is different. It’s sneakier. The information was once true. That’s what makes it so dangerous.
What Is Temporal Hallucination in AI?
Temporal hallucination happens when an AI model presents outdated information as if it’s currently accurate. The model doesn’t “know” time has passed. It mixes timelines, misplaces events, or confidently delivers yesterday’s truth as today’s fact.
Here’s the thing — large language models (LLMs) are trained on data with a fixed cutoff. Once training ends, the model’s internal knowledge freezes. The world keeps moving. The model doesn’t.
So when someone asks, “Who runs Company X?” or “When did COVID-19 start?” — the model doesn’t pause to say, “Wait, let me check if this is still accurate.” It generates what statistically sounds right based on its training data. And sometimes, that data is months or years out of date.
According to research from leading NLP surveys, once an LLM is trained, its internal knowledge remains fixed and doesn’t reflect changes in real-world facts. This temporal misalignment leads to hallucinated content that can appear completely plausible — right up until it causes real damage.
The three most common forms of temporal hallucination you’ll see in production AI systems:
- Outdated leadership or personnel information — “The CEO of X is…” (he left 18 months ago)
- Wrong event timelines — “COVID-19 started in 2018” or placing a product launch in the wrong year
- Stale policy or pricing data — confidently quoting a rate or rule that’s no longer in effect
None of these sound like hallucinations. They sound like facts. That’s the problem.
Why Temporal Hallucination Is More Dangerous Than Other AI Errors
Most AI errors are obvious. A model that writes “the moon is made of cheese” fails immediately. You know something went wrong.
Temporal hallucination doesn’t fail visibly. It passes. It reads well. It’s grammatically correct and contextually coherent. The only thing wrong with it is that it’s no longer true — and neither the user nor the system knows that without external verification.
The business risk is real. In legal and compliance contexts, courts worldwide issued hundreds of decisions in 2025 addressing AI hallucinations in legal filings, with incorrect AI-generated citations wasting court time and exposing firms to liability. In healthcare, hallucination rates in clinical AI applications can reach 43–67% depending on case complexity.
Here’s what most people miss: your users trust AI outputs more when they sound confident. And temporal hallucinations are always confident. The model doesn’t hedge. It doesn’t say, “This might be outdated.” It states it as fact — with full grammatical authority.
For CEOs and CTOs deploying AI in customer-facing roles, this is the scenario that keeps you up at night. Not a system that breaks. A system that works — just with the wrong information.
The Root Cause: Why LLMs Get Stuck in Time
Understanding why temporal hallucination happens helps you build the right defences.
LLMs learn from massive datasets collected up to a specific date. After that cutoff, training stops. The model is essentially a very sophisticated snapshot of the world as it existed at a point in time. When you deploy that model six months later — or two years later — that gap becomes the source of risk.
There’s another layer to this. Research shows that models are especially prone to hallucination when dealing with information that appears infrequently in training data. Lesser-known regional facts, niche industry data, recent regulatory changes — these are exactly the areas where temporal hallucination strikes hardest, because the training signal was already thin to begin with.
The real question is: what do you do about it?
How to Fix Temporal Hallucination: 3 Proven Approaches
You don’t need to rebuild your AI stack from scratch. The fixes are architectural, not philosophical. Here’s what actually works.
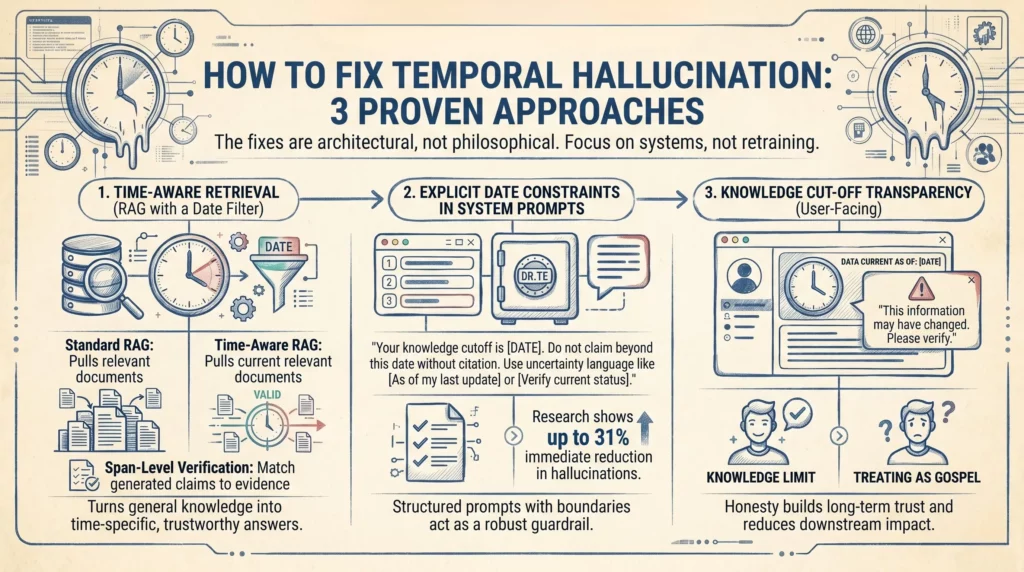
1. Time-Aware Retrieval (RAG with a Date Filter)
Retrieval-Augmented Generation (RAG) is already one of the strongest tools against hallucination in general. But for temporal hallucination specifically, you need to take it one step further: date-filtered retrieval.
Standard RAG pulls in relevant documents. Time-aware RAG pulls in relevant documents that are current. You add a temporal filter to your retrieval layer — documents older than your defined threshold simply don’t get served to the model.
This is the difference between “here’s everything we know about X” and “here’s everything we know about X that was written in the last 12 months.” For a customer service AI, an internal knowledge assistant, or a compliance tool — this distinction is everything.
One important note: even well-curated retrieval pipelines can still fabricate citations. The most reliable systems now add span-level verification, where each generated claim is matched against retrieved evidence and flagged if unsupported. That’s the extra layer that turns a good RAG system into a trustworthy one.
2. Explicit Date Constraints in System Prompts
This one is simpler than it sounds, and it works faster than most technical teams expect.
When you design your system prompt — the instruction set that tells the AI how to behave — you include explicit temporal boundaries. Something like:
“Your knowledge cutoff is [Date]. Do not make claims about events, people, or policies beyond this date without citing a retrieved source. If you are uncertain about whether information is current, say so explicitly.”
Research on AI guardrails shows that structured prompts with explicit constraints can reduce hallucinations by around 31% immediately — with no model retraining required. That’s not a trivial gain. For a deployed enterprise AI, that’s the difference between a reliable tool and a liability.
Combine this with an instruction to use uncertainty language when the model isn’t sure — “as of my last update” or “please verify this is still current” — and you’ve built in a self-disclosure mechanism that significantly reduces the risk of confident, incorrect temporal claims.
3. Knowledge Cut-Off Transparency (User-Facing)
The third fix operates at the interface level rather than the model level. And it’s often overlooked because it feels like a UX decision rather than an AI safety one.
When users understand that an AI has a knowledge cutoff, they apply appropriate scepticism. When they don’t, they treat everything as gospel. This isn’t about hiding limitations — it’s about honesty that builds long-term trust.
Best practice: display the model’s knowledge cutoff date clearly in the interface. Add a note when the AI is answering a question that’s likely time-sensitive. For high-stakes outputs — anything involving personnel, pricing, regulation, or recent events — surface a prompt that says: “This information may have changed. Please verify before acting.”
It feels like a small thing. It fundamentally changes how users interact with AI outputs — and it dramatically reduces the downstream impact of any temporal errors that do slip through.
What This Looks Like in Practice: Industry Examples
Let’s ground this in real scenarios, because temporal hallucination isn’t an abstract research problem. It shows up in production systems every day.
B2B SaaS customer support: An AI assistant trained on product documentation from early 2023 confidently tells a user that a particular integration is available — an integration that was deprecated eight months ago. The user spends three hours trying to configure something that no longer exists. Support ticket created. Trust eroded.
Healthcare & Life Sciences: A clinical AI references treatment guidelines that have since been updated. The dosage recommendation it cites was revised following new safety data. In this domain, outdated is not just inconvenient — it’s potentially dangerous.
Automotive & Manufacturing: A compliance AI cites a regulatory requirement that was amended last quarter. A procurement decision is made on the basis of a rule that no longer applies exactly as stated.
In every case, the AI did exactly what it was designed to do. It generated a confident, coherent, grammatically correct response. The problem wasn’t that the system failed. The problem was that the system succeeded — with stale data.
Building Temporal Awareness Into Your AI Strategy
Here’s the honest truth about temporal hallucination: you can’t eliminate it entirely. Researchers have formally proven that some level of hallucination is mathematically inevitable in current LLM architectures. But you can contain it. You can engineer around it. And you can build systems where the failure mode is a transparent acknowledgment of uncertainty — not a confident, damaging wrong answer.
The companies that are winning with AI in 2025 and beyond aren’t those deploying the most powerful models. They’re deploying the most governed models — systems wrapped in the right constraints, retrieval layers, and transparency mechanisms that make AI output trustworthy at scale.
At Ai Ranking, we help businesses build AI systems that perform reliably in the real world — not just in demos. Temporal hallucination is one of the ten AI failure patterns we audit for in every enterprise deployment. Because a model that sounds right but isn’t is worse than a model that stays silent.
Ready to assess your AI stack for temporal and other hallucination risks? Let’s talk.
Frequently Asked Questions
1. What is temporal hallucination in AI?
Temporal hallucination is when an AI model presents outdated information as current fact — for example, citing a CEO who left two years ago or referencing a policy that has since changed. It occurs because LLMs have a fixed training cutoff and no awareness that time has passed.
2. How is temporal hallucination different from regular AI hallucination?
Regular hallucination involves completely fabricated facts. Temporal hallucination involves facts that were once true but are now outdated. This makes it harder to detect because the information sounds plausible and historically accurate.
3. What causes temporal hallucination in large language models?
LLMs are trained on data up to a specific cutoff date. After training, their internal knowledge is frozen. When deployed months or years later, they continue referencing outdated information without knowing it has changed — causing temporal hallucination.
4. What are examples of temporal hallucination in AI?
Common examples include: stating an incorrect CEO or leadership team, placing historical events in the wrong year, referencing discontinued products as available, or citing regulations that have since been amended.
5. How do you fix temporal hallucination in AI?
The three primary fixes are: (1) time-aware retrieval (RAG with date filters), (2) explicit date constraints in system prompts, and (3) knowledge cut-off transparency displayed to users — so they know when to verify time-sensitive information.
6. What is time-aware retrieval in AI?
Time-aware retrieval is a version of Retrieval-Augmented Generation (RAG) that applies a date filter to retrieved documents — only serving the model current, within-date-range information to prevent outdated content from entering its responses.
7. Can prompt engineering reduce temporal hallucination?
Yes. Structured system prompts with explicit date constraints and uncertainty instructions can reduce hallucination rates by around 31% immediately, without requiring any model retraining.
8. Which industries are most at risk from temporal hallucination?
Healthcare, legal, financial services, and compliance-heavy industries face the highest risk — because outdated information in these domains can lead to regulatory violations, incorrect clinical guidance, or invalid legal references.
9. Is temporal hallucination the same as knowledge cutoff?
They are related but not identical. The knowledge cutoff is the date after which an LLM has no training data. Temporal hallucination is the specific failure that occurs when the model presents pre-cutoff information as currently valid — without acknowledging the gap.
10. How can businesses detect temporal hallucination in their AI systems?
Businesses can detect it through: regular audits comparing AI outputs against current verified sources, span-level claim verification pipelines, and monitoring outputs in time-sensitive categories (leadership, pricing, regulation, product availability) with a human-in-the-loop review layer.

AI Performance Metrics: Why Your AI Is Losing Money
Most leaders think deploying AI is the hard part. It is not. Running AI without any way to measure whether it is actually working, that is the hard part. And right now, a startling number of organizations are doing exactly that.
Here is what most people miss: deploying an AI agent without performance metrics is not neutral. It is a slow bleed. Every day the system runs without measurement, errors go undetected, costs drift upward, and the gap between what you expected and what you are getting quietly widens. By the time someone notices, the damage is already embedded in your operations.
This article is for CEOs, CTOs, and technology leaders who are serious about getting real business value from AI, not just deploying it and hoping for the best. If your AI agents are live but you cannot answer the question “Is this working and how do we know?”, keep reading. We are going to change that.
Why “No Metrics for AI Performance” Is Sign Number Eight on the AI Readiness Watchlist
When we talk about the 15 signs your organization is not ready for AI agents, the absence of AI performance metrics sits at number eight for a reason. It sits squarely in the middle because it is the hinge. Everything before it, from scattered knowledge and undocumented workflows to poor data quality and no approval layers, creates conditions where AI fails. But without measurement, you never know which of those failures is happening, or how badly.
The phrase “what gets measured gets optimized” sounds like a motivational poster. In AI operations, however, it is a survival principle. Without a measurement layer, your AI agent has no feedback mechanism. It cannot improve because nothing tells it, or you, when it is wrong. Mistakes that a human reviewer would catch in a traditional workflow scale silently through automated systems until they surface as a business problem rather than an AI problem.
This is the real danger. Not that your AI will fail dramatically on day one. But that it will fail quietly, incrementally, across thousands of interactions, and you will have no idea until the downstream consequences surface in your P&L, your customer satisfaction scores, or your compliance audit.
What the Data Actually Says About AI Measurement
The numbers here are genuinely alarming. Moreover, they deserve to be seen clearly rather than buried in footnotes.
McKinsey’s research confirms that fewer than 20% of organizations track well-defined KPIs for their GenAI solutions. That means more than four out of five organizations are running AI without a structured measurement framework. According to the same research, scaling AI without defined metrics is consistently cited as the primary reason AI programs stall out before they deliver value.
Gartner’s AI Maturity Survey found that only 63% of high-maturity organizations, the ones already considered advanced in AI adoption, run financial risk analysis, ROI analysis, and measure customer impact in any structured way. Think about what that means for organizations still in earlier stages of the journey.
Deloitte’s State of GenAI 2024 report found that 41% of business leaders openly admit they struggle to measure AI’s impact on their operations. IBM’s ROI of AI Report, conducted by Morning Consult, put the positive ROI figure at just 47%. More than half of companies investing in AI cannot confirm they are seeing returns.
McKinsey’s Superagency in the Workplace report found that 92% of companies plan to increase their AI investments over the next three years, while only 1% of leaders describe their companies as mature in AI deployment. The message is clear: AI investment is accelerating, but AI operating maturity is still far behind.
This is not an AI problem. It is a management problem. And it is one that can be fixed.
What “No AI Performance Metrics” Actually Looks Like Inside an Organization
It rarely looks like chaos. That is part of what makes it so hard to catch. Here is what it actually looks like day to day.
Your dashboards show activity, not outcomes. You can see how many tasks the AI agent processed, how many queries it responded to, how many workflows it touched. What the dashboard does not show is whether any of that activity produced a better result than what you had before. Volume is not value.
Improvement happens by accident when it happens at all. Without baselines and benchmarks, you have no way to distinguish a genuine performance gain from random variance. Your AI might get better over time, or it might quietly degrade. You will have no way to tell the difference until something breaks loudly enough to notice.
The AI team and the business team are measuring different things. Engineers track uptime, latency, and model accuracy. Business leaders track revenue, customer satisfaction, and operational costs. With no shared measurement framework, these two groups are essentially working on different problems and calling them the same project.
Errors compound before anyone catches them. This connects directly to the risk of running AI without an approval or review layer in your workflows. If you want to understand how unreviewed AI outputs scale into operational risk, the breakdown of what happens when no approval or review layer exists in your AI setup makes the connection concrete. Without metrics, you cannot see errors accumulating. Without a review layer, you cannot stop them from spreading.
The IBM and MD Anderson Case Study: A Sixty-Two-Million-Dollar Lesson in Missing Metrics
When people ask for a real-world example of what it costs to run AI without a clear measurement and validation framework, this is the one that belongs in every boardroom conversation.
IBM and MD Anderson Cancer Center partnered to build the Oncology Expert Advisor, a Watson-powered advisory tool designed to assist oncologists in clinical decision-making. The project was well-funded, medically ambitious, and backed by genuine intent to improve patient care. A prototype was tested in the leukemia department.
MD Anderson cancelled the project in 2016 after spending approximately sixty-two million dollars. As reported by IEEE Spectrum, the system never became a commercial product. The project ran into serious difficulties with the realities of clinical data, including the complexity of electronic health records, validation challenges, and the absence of clear performance checkpoints that would have allowed teams to catch integration problems early and course-correct before costs escalated.
The lesson is not that AI cannot work in healthcare. It absolutely can, and does. The lesson is that high-stakes AI needs clear success criteria, clinical validation standards, integration readiness checks, and measurable performance milestones before it moves toward production deployment. Without those checkpoints built in from the start, you have no mechanism to identify failure until the budget is already spent.
Source: IEEE Spectrum, “IBM Watson, Heal Thyself: How IBM Overpromised and Underdelivered on AI Health Care.”
The AI Performance Metrics That Actually Move the Needle
Here is where most measurement frameworks go wrong. They measure what is easy to pull from a system log rather than what tells you whether the AI is creating business value. Let us fix that.
Accuracy and Quality Metrics
First, you need to know whether the AI is producing correct, useful outputs. The most practical ones to track are task completion rate (did the agent finish what it was asked to do), recommendation acceptance rate (when the AI suggests something, how often do humans agree it was right), and error rate per thousand interactions. Furthermore, if your AI is producing outputs that humans routinely override or correct, that pattern is itself a critical data point.
Efficiency Metrics
Beyond accuracy, efficiency metrics connect AI activity directly to cost and speed. Compare average handling time before and after AI deployment on the same process. Track cost per task completed. Measure the ratio of AI-resolved interactions to human-escalated ones. As a result, you will know quickly whether the AI is automating volume while also increasing cost per unit, which happens more often than most leaders expect.
Business Impact Metrics
These are, ultimately, the ones that justify the budget conversation. How much revenue has AI-assisted decisions influenced? What has happened to customer satisfaction scores in workflows the AI now touches? Are operational costs in targeted areas trending down or up? In short, these metrics transform AI from an IT project into a business strategy.
Risk and Safety Metrics
Finally, risk and safety metrics are consistently the most overlooked category. Track the rate at which AI-generated outputs require human correction after the fact. Monitor escalation volumes for signals that the AI receives requests outside its reliable range. Run regular compliance checks on AI-involved decisions. These metrics are your early warning system, and without them, you are operating blind.
If your data quality is inconsistent across systems, all of these metrics will be unreliable at the source. This is why addressing multiple versions of truth in your data is not a separate workstream from building an AI measurement framework. They are the same problem looked at from two angles.
Why Most AI Measurement Frameworks Fail Before They Start

Here is the catch that most implementation guides skip over. Building a metrics framework after deployment is significantly harder than building it before. And most organizations try to do exactly that.
By the time you realize you need measurement, your AI has already been running for weeks or months. You have no baseline to compare against. The teams closest to the pre-AI process have moved on to other priorities. Moreover, real-world inputs have already shaped the AI’s behavior in ways that teams never benchmarked, so there is nothing meaningful to measure improvement against.
This is why the measurement conversation needs to happen before go-live, not after. When you design the AI agent’s workflow, that is when you define success. What does this agent need to accomplish for this deployment to be worthwhile? Write it down in specific, measurable terms. That sentence becomes your first performance metric.
The other failure pattern is assigning measurement responsibility to nobody in particular. Metrics without owners are decoration. Someone on your team needs to own each KPI, report on it regularly, and have the authority to escalate when it moves in the wrong direction. If measurement is everyone’s responsibility, it will quickly become no one’s.
This connects to a broader readiness challenge around ownership in AI programs. The same dynamic that creates problems when no one owns AI outcomes at the strategic level plays out identically at the metrics level. Accountability has to be assigned, not assumed.
How to Build a Practical AI Performance Measurement Framework in Four Steps
You do not need a six-month consulting engagement to get started. Here is a practical sequence that works.
Step one: Define success before deployment. For each AI agent or workflow, write one to three specific statements that describe what success looks like. Keep them concrete. For instance, “The AI will resolve 65% of Tier 1 support queries without human escalation” is a success statement. “The AI will help improve customer service” is not.
Step two: Establish your baseline. Pull the current performance data for the process your AI is replacing or augmenting. How long does it take? How accurate is it? What does it cost? How satisfied are customers with the outcome? That data is your starting point for every future comparison.
Step three: Build measurement into the rollout schedule. Do not treat monitoring as an afterthought. Therefore, schedule weekly check-ins in the first month, moving to monthly reviews as performance stabilizes. Make AI performance a standing agenda item in your technology and operations reviews.
Step four: Assign ownership and act on the data. Every metric needs a named owner. Every review needs to end with a decision, whether to stay the course, adjust the AI’s configuration, escalate a data quality issue, or retrain on new inputs. Consequently, measurement only creates value when it drives action.
If you are finding that your AI agents struggle because of data fragmented across systems, the underlying problem of scattered knowledge silently sabotaging your AI is worth addressing alongside your measurement buildout. Metrics built on fragmented data will give you fragmented insights.
The Leadership Reality Check
Let us be honest about something. Metrics programs do not fail because the metrics are wrong. They fail because leadership does not review them consistently enough to create accountability.
Gartner’s research found that only 27% of executives have a comprehensive AI strategy, and just 20% believe their workforce is actually ready for AI at scale. As a result, that gap in strategic preparedness shows up most visibly in measurement. When leadership is not looking at AI performance data, no one below them will treat it as a priority either.
If you are a CTO or CIO reading this, the most direct thing you can do to accelerate your AI measurement maturity is put AI performance metrics in your regular business reviews. Not as a technology report. As a business report. Accuracy rates, cost per task, escalation volumes, and business outcome trends sitting in the same review as revenue and customer satisfaction. That framing changes how every team in the building thinks about AI accountability.
In addition, if your AI agents operate without real-time data, the measurement challenge becomes even harder because your AI outputs outdated information before it ever reaches a decision-maker. The full picture of why AI agents fail without real-time data access is a related read that fills in this gap.
From Measurement to Continuous Improvement
The point of tracking AI performance metrics is not to generate reports. It is to create a closed loop where your AI system gets progressively better over time.
High-maturity AI organizations understand this well. Gartner’s research found that 45% of organizations with strong AI maturity keep their AI initiatives in production for three or more years, against just 20% of low-maturity organizations. The difference is almost never the sophistication of the initial model. Instead, it is whether the organization has the measurement and iteration infrastructure to keep improving after launch.
The loop looks like this: deploy with defined success criteria, measure against them, identify the gap between actual and target performance, adjust, and measure again. That cycle, repeated consistently, is what separates AI programs that deliver compounding value from those stuck permanently in pilot phase.
Without performance data, however, this loop cannot close. You cannot adjust what you cannot see. And if your documentation of how those workflows are supposed to run does not match how they actually run, your measurement baseline rests on false assumptions. The full picture of what happens when your documentation lies about how work actually gets done explains why this matters before you build any measurement framework.
The Connection Between Measurement and Every Other AI Readiness Challenge
Here is what most people miss when they think about AI performance metrics as a standalone issue. Measurement does not fix your AI readiness gaps in isolation. Rather, it makes every other gap visible.
Poor data quality shows up immediately in your accuracy metrics. They will start reflecting noise before you even realize the source of the problem. Beyond accuracy, if your AI agents are relying on conflicting data across multiple systems, inconsistent outputs will show up in your error rates as well. Processes buried in people’s heads rather than documented anywhere cause your AI’s task completion rate to plateau at a frustratingly low ceiling. Similarly, a security model built only for human users and not for autonomous agents will cause your risk metrics to flash warnings before your security team even identifies the source.
This is why measurement is the pivot point in the AI readiness journey. Not because it solves everything, but because it makes everything else solvable. You cannot fix what you cannot see. And right now, most organizations cannot see nearly enough.
The connection between real-time data access and measurement accuracy is also worth calling out explicitly. If your AI agents are acting on data that is hours or days out of date, the actions they take will look correct in the moment and incorrect in the outcome. Understanding why real-time data access is the hidden reason AI agents struggle will save you from building measurement frameworks on top of a stale data problem.
And if your workflows are undocumented and buried inside individual employees, your AI agent will hit invisible walls that your metrics will expose but that your team will struggle to diagnose without better process documentation.
Conclusion: The AI You Cannot Measure Is the AI You Cannot Trust
Here is the real shift in thinking we want to leave you with. Measurement is not a reporting function. It is a trust function.
You cannot trust an AI system you cannot measure. You cannot justify continued investment in something you cannot prove is working. And you cannot build organizational confidence in AI adoption when the people closest to the work have no visibility into whether the AI is helping or hurting.
The good news is that this is one of the most actionable AI readiness gaps on the list. You do not need a perfect framework on day one. You need clear success criteria, an honest baseline, a consistent review cadence, and named owners for each metric. Start there, and build from it.
At Ysquare Technology, we help organizations design and deploy AI agents with the measurement infrastructure built in from the start, not bolted on after the problems show up. If your AI is running without metrics, or your metrics are tracking the wrong things, we can help you build a framework that connects your AI performance directly to business outcomes.
Connect with us on Ysquare Technology’s LinkedIn page or visit ysquaretechnology.com to start the conversation. Your AI is either getting better every week or quietly drifting. Measurement is how you make sure you know which one is happening.
Read More

Ysquare Technology
25/05/2026

Why Security Built Only for Humans Will Break Your AI Agent Strategy
Your firewall works. Your access controls look clean. Your IT team passed the last compliance audit without a single flag. So why does your AI agent keep doing things it was never supposed to do?
Here’s the catch. Most enterprise security models were designed with one assumption at the center: a human is always in the loop. Someone logs in. Another person requests access. A manager approves a transaction. Every control, every audit trail, and every permission layer centers on the idea that a person is making the decision.
AI agents do not work that way.
When you introduce autonomous AI agents into your workflows, you are not just adding a new tool. You are introducing a new type of actor into your systems — one that operates continuously, makes decisions at machine speed, and does not wait for someone to click “approve.” If your security model has not kept up, you are running a powerful autonomous system through a framework that was never built to contain it.
This is one of the most overlooked risks in enterprise AI adoption today. And it is silently growing in organizations that believe they are ready for AI agents when, in reality, they are only ready for AI tools that humans control.
What “Security Built Only for Humans” Actually Means

Traditional enterprise security is built on a few foundational ideas. Role-based access control (RBAC) gives specific users specific permissions. Multi-factor authentication (MFA) verifies identity at login. Audit logs track which employee took which action. Privileged access management (PAM) ensures only authorized people can access sensitive systems.
Every single one of these controls assumes a human being is the actor.
When an AI agent enters the picture, it does not log in the way an employee does. There is no ticketing system request. Instead, it operates across dozens of tools and data sources simultaneously, making hundreds of micro-decisions in the time it takes a human to read one email. Furthermore, because teams typically gave it broad permissions during setup to work efficiently, it often has access to far more than it actually needs for any single task.
This is what security built only for humans looks like when it meets AI: the agent operates under a user account or service account, inheriting whatever permissions that account holds. There is no granular control over what the agent can actually do versus what the account technically allows. Nobody built a system to monitor autonomous action at the speed AI operates.
If you have also not addressed issues like scattered knowledge across tools and teams, your AI agent may be accessing data from systems it never should have touched in the first place, simply because nobody ever tightened permissions to match task-specific needs.
Why Traditional Security Controls Fail AI Agents Specifically
Let’s be honest about the gap here. Traditional security controls fail AI agents for three concrete reasons.
First, there is no identity model for autonomous actors. Your security infrastructure knows how to handle Bob from finance. It does not know how to handle an AI agent that is simultaneously querying your CRM, drafting emails, updating records, and sending Slack messages, all without a human in the loop at any step. The agent lacks a distinct identity with its own purpose-built constraints.
Second, access is too broad by design. AI agents need access to function. In the rush to get them operational, teams frequently give agents overly permissive service accounts because it is faster than building granular controls. The result is an autonomous system with access to data and actions far beyond what its actual tasks require. Security researchers call this the principle of least privilege failure — and it is rampant in early AI deployments.
Third, traditional monitoring cannot keep pace with autonomous action. Your SIEM (Security Information and Event Management) system is excellent at flagging unusual human behavior. However, it cannot distinguish between an AI agent doing its job correctly and an AI agent doing something it should not. When agents operate at machine speed, by the time a human reviews the logs, the damage may already be done.
This connects directly to a point worth noting: if your organization is also running without a proper approval or review layer for AI decisions, you are compounding the risk substantially. Two missing layers — security and oversight — do not just add up. They multiply.
The Risks You Are Probably Not Thinking About
Most security conversations about AI agents focus on external threats: prompt injection attacks, adversarial inputs, data poisoning. Those are real and worth addressing. However, the more immediate risk for most organizations is internal and architectural.
When an AI agent inherits broad access and no behavioral guardrails, a few scenarios become dangerously plausible. For example, the agent accesses and transmits data to external tools or APIs it was configured to work with, but nobody reviewed whether those integrations were appropriate for the sensitivity of that data. In addition, the agent takes actions in connected systems based on decisions rooted in multiple conflicting versions of the same data, producing outputs that are technically authorized but factually wrong. Or the agent, following its instructions correctly, triggers a cascade of automated actions across systems that no human would have approved if they had been paying attention.
None of these scenarios require a hacker. They are entirely self-inflicted.
Consequently, there is also the compliance dimension to consider. In regulated industries — healthcare, finance, legal — every data access and every decision needs to be traceable and defensible. An AI agent operating through a general service account with no dedicated audit trail is an audit disaster waiting to happen.
Moreover, for organizations where undocumented workflows still live inside people’s heads, this risk is even higher. An AI agent cannot follow a process that was never formalized, and the resulting improvisations under insufficient security controls can expose data in ways nobody anticipated.
Industry Data: The Numbers That Should Concern You
The data on AI security failures is starting to come in, and it is not reassuring.
To begin with, according to IBM’s Cost of a Data Breach Report 2024, the average cost of a data breach reached $4.88 million, a 10% increase from 2023 and the highest figure IBM has recorded. IBM also found that organizations using AI extensively in security operations detected and contained breaches significantly faster, showing how modern security automation can reduce breach impact and response delays. Source: IBM Cost of a Data Breach Report 2024
Additionally, Gartner predicts that by 2028, 25% of enterprise GenAI applications will experience at least five minor security incidents per year, up from just 9% in 2025, as agentic AI adoption and immature security practices continue to expand the attack surface. Source: Gartner, April 2026
Perhaps most striking, a Cloud Security Alliance and Oasis Security survey found that 78% of organizations do not have documented and formally adopted policies for creating or removing AI identities — meaning most enterprises cannot even account for the non-human actors already operating inside their systems. Source: Cloud Security Alliance, January 2026
Taken together, these are not edge cases. They represent the mainstream trajectory of AI adoption without a matching evolution in security thinking.
Real-World Case Study: Samsung’s ChatGPT Data Leak
Company: Samsung Electronics
What happened: In early 2023, Samsung engineers began using ChatGPT to assist with internal code review and debugging tasks. Within weeks, three separate incidents of sensitive data leakage occurred. In one case, an employee submitted proprietary source code to ChatGPT for review. In other reported cases, employees shared internal meeting content and proprietary technical information with AI tools.
None of this was the result of malicious intent. It was the direct result of employees using an AI tool with no security guardrails, no defined boundaries around data sharing with external AI systems, and no access control layer between sensitive internal data and the AI processing it.
Key outcome: Samsung banned internal ChatGPT use shortly after and began developing its own internal AI tools with security controls built in. Samsung was concerned that sensitive data sent to external AI platforms would be difficult to retrieve or delete once uploaded, creating a long-term confidentiality risk with no reliable remediation path.
Why this matters for AI agents: Samsung’s engineers were using AI as a tool they manually interacted with. AI agents operate autonomously. If a manually operated AI tool caused this scale of exposure, an autonomous agent with broad data access and no behavioral guardrails represents a fundamentally larger risk profile.
Verified Sources: The Verge, “Samsung bans employee use of AI tools like ChatGPT after data leak” — theverge.com/2023/5/2/23707796/samsung-chatgpt-ban | AI Incident Database, Incident 768 — incidentdatabase.ai/cite/768
What an AI-Ready Security Model Actually Looks Like
Building security for AI agents is not about replacing your existing framework. Rather, it is about extending it to account for a new type of actor. Here is what that means in practice.
Dedicated identity for every AI agent. Each agent should have its own service identity with purpose-built permissions scoped only to what that agent needs for its specific tasks. Not a shared service account. Not a borrowed user account. Its own identity with its own access log.
Behavioral monitoring, not just access monitoring. You need systems that track what the agent actually does, not just whether it had permission to do it. Specifically, monitoring for anomalous sequences of actions, unusual data volumes, or patterns that deviate from the agent’s defined task scope are all critical.
Data classification and agent access tiers. Not every agent should have access to every data tier. As a result, you need explicit rules around what categories of data each agent can interact with, enforced at the infrastructure level, not just through configuration trust.
Defined operational boundaries. As we have explored in the context of real-time data access and AI agents, agents need to know what systems they are allowed to touch, in what sequence, and under what conditions. These are not just workflow guidelines. They are security boundaries.
Human escalation triggers. For high-stakes or sensitive actions, agents should be configured to pause and escalate to a human decision-maker rather than proceed autonomously. This is not a weakness in your AI strategy. In fact, it is a mature, defensible design choice.
Practical Steps to Start Closing the Gap
You do not need to rebuild your entire security architecture before deploying AI agents. However, you do need to move deliberately through a few foundational steps.
Start by auditing every AI agent’s current access permissions. Document what each agent can touch, what it actually touches during normal operation, and where those overlap. The difference between “can access” and “needs access” is where your immediate risk lives.
Next, establish a dedicated identity management practice for non-human actors. Many organizations already have frameworks for managing service accounts. Therefore, extend and formalize this for AI agents specifically, giving each agent its own identity and its own audit trail.
Then define and document what actions are in scope for each agent. This connects directly to the broader challenge of making your documentation reflect how work actually gets done. An agent operating against undocumented process boundaries is a security problem as much as an operational one.
Finally, integrate agent behavior monitoring into your existing SIEM or observability stack. That way, you have a single view of what your human and non-human actors are doing, with alerting configured for patterns that deviate from expected task behavior.
Conclusion
The organizations that get AI agents right over the next two years will not be the ones with the most powerful models. They will be the ones that built the right foundations before scaling.
Security built only for humans is not a small gap to patch. It is a structural mismatch between your risk environment and your risk controls. AI agents are already operating in enterprises that were never designed to contain them, and the incidents that result are increasing in both frequency and cost.
The good news is that the path forward is clear. Treat AI agents as distinct actors that need their own identity, their own access controls, and their own behavioral monitoring. Build boundaries that are enforced, not assumed. And do not confuse “no incident yet” with “no risk.”
If you are mapping out AI agent readiness for your organization, it helps to look at these issues together. From why scattered knowledge silently limits AI performance to the structural reasons real-time data access shapes AI agent reliability, security is one piece of a larger picture.
Ready to evaluate where your security model stands for AI agents?
Connect with the Ysquare Technology team on LinkedIn to start that conversation.
Read More
Ysquare Technology
22/05/2026

Multiple Versions of Truth Are Quietly Killing Your AI Strategy
Your AI strategy may look strong on paper. The roadmap is approved, the tools are selected, and the automation goals are clear. But if your CRM, ERP, finance dashboard, and operations systems all show different answers, your AI strategy is already standing on unstable ground.
This is the real danger of multiple versions of truth. It is not just a reporting problem or a data hygiene issue. It is a business risk that directly affects decision-making, AI readiness, and the ability to scale automation with confidence. Before companies ask what AI can do for them, they need to ask a more basic question: can our data be trusted?
What Multiple Versions of Truth Actually Means in Business

The phrase “multiple versions of truth” sounds technical, but the reality is painfully simple. It means different parts of your organization are working from different datasets that contradict each other.
Your sales team calls a customer “active.” Your support team has them marked “churned.” Your billing system still has an open invoice. Which version is real? Honestly, none of them are fully right.
This happens for a few reasons. Data silos are a big one. When departments build their own spreadsheets, maintain their own CRM records, and create their own reporting dashboards without a shared data governance framework, you end up with fragmented truths that slowly pull your operations apart.
Conflicting data is not always caused by careless teams. Often it comes from legacy systems that were never designed to talk to each other, manual data entry that introduces small errors over time, or integration gaps where two platforms sync inconsistently. The result is the same regardless of the cause: your decisions, your workflows, and your AI agents are all working from unreliable ground.
If you want to understand how scattered information creates this problem from the roots up, this deeper look at why scattered knowledge is silently sabotaging your AI is worth your time.
Why Conflicting Data Is an AI Killer, Not Just a Reporting Problem
Here is the catch that most AI implementation guides skip over. AI agents are only as reliable as the data they are trained on or given access to. When you feed conflicting data into an AI system, you are not just getting imperfect outputs. You are actively teaching the system to trust bad information.
Think about what an AI agent actually does. It reads your data, identifies patterns, makes decisions, and triggers actions. If the customer record says one thing and the billing record says another, the AI will either pick one arbitrarily, get confused and fail, or worse, act on the wrong version and create a downstream problem you do not catch for weeks.
This is one of the main reasons AI automation projects underdeliver. It is rarely the AI model itself that fails. It is the data infrastructure underneath it.
According to a McKinsey report on AI adoption, one of the top barriers to scaling AI across enterprises is not the technology itself but the quality and consistency of the underlying data. Companies that manage to solve their data consistency problems before deploying AI see significantly better results from their investments.
The issue is especially sharp when you consider real-time operations. If an AI agent is making decisions based on data that is stale, duplicated, or in conflict with another system, it is essentially flying blind. We explored this problem in detail when looking at why real-time data access is the hidden reason your AI agents are failing.
Real-World Example: How Target Canada Collapsed Under Data Inconsistency
Target’s expansion into Canada is one of the most well-documented data management failures in retail history. When Target opened 133 Canadian stores in 2013, they migrated enormous amounts of product data into their new SAP system. The problem was that the data was riddled with errors and inconsistencies.
Product dimensions were wrong. Descriptions did not match. Cost data had thousands of inaccuracies. The system was receiving one version of truth from suppliers, another from logistics partners, and another from internal teams. Nobody could agree on what was correct.
The result was catastrophic. Shelves were either completely empty or massively overstocked. Customers came in expecting products they had seen advertised and left empty-handed. Inventory systems showed items as available that simply were not there.
Target Canada shut down entirely in 2015, just two years after opening. The losses totaled over $2 billion. A Harvard Business Review analysis of the failure pointed directly at data quality and management failures as a root cause. The IT and logistics systems could not function because the foundational data was too inconsistent to support reliable operations.
The lesson here is brutal but clear. No operational system, and certainly no AI system, can compensate for broken data at the source. Multiple versions of truth do not just create reporting headaches. They bring entire business operations to a halt.
Source: Harvard Business Review, “How Target Lost Canada”
The Link Between Data Silos and Multiple Versions of Truth
Data silos are where multiple versions of truth are born. When your marketing team uses HubSpot, your finance team uses a different system, your operations team has a custom database, and your customer service team is still running on spreadsheets, you are not building one picture of your business. You are building four separate pictures that often contradict each other.
Gartner research has consistently highlighted that organizations with poor master data management are significantly less effective at digital transformation. The reason is straightforward: transformation requires coordination, and coordination requires agreement on what is true.
Here is what makes data silos particularly dangerous for AI readiness. AI agents are designed to work across functions. They need to pull customer data, check inventory, verify pricing, confirm approvals, and trigger actions across multiple systems in a single workflow. If every system has its own version of the facts, the AI cannot string those steps together reliably.
This also ties directly into the documentation problem. When processes live in people’s heads or in outdated wikis rather than in a consistent, maintained system of record, AI agents cannot follow them. We covered that specific problem in our analysis of why undocumented workflows stop AI agents from automating your business.
What a Single Source of Truth Actually Looks Like in Practice
A single source of truth is not a single database. That is a common misunderstanding. It is a principle, not a piece of software. It means that for any given data point, there is one authoritative place where that data lives and is maintained. Every other system either refers to it or syncs from it.
Getting there requires a few foundational things.
First, you need data governance. That means deciding who owns each data type, who has permission to edit it, and what the process is for resolving conflicts when they appear. Without ownership, you get competing versions with no referee.
Second, you need integration architecture that maintains consistency. If two systems need to share customer data, they should sync from one master record rather than each maintaining their own copy. Real-time syncing with conflict resolution rules is what separates clean data environments from messy ones.
Third, you need audit trails. When a piece of data changes, you need to know who changed it, when, and why. This is not just good governance. It is essential for AI accountability, especially as AI agents start making decisions based on that data.
If you have already deployed AI agents and are starting to see inconsistent outputs, conflicting data is almost certainly part of the problem. You can read more about how this connects to broader AI readiness challenges in our piece on scattered knowledge and AI agents readiness.
How Multiple Versions of Truth Break AI Agent Workflows Specifically

Let us get specific for a moment because this matters for anyone actively building or buying AI automation.
An AI agent handling order management needs to know the current stock level, the correct product specifications, the right pricing for the customer tier, and the approval status of the order. If your inventory system says 50 units are available but your warehouse management system says 12, the AI agent will either order too much, confirm availability it cannot deliver on, or stop entirely because it cannot reconcile the conflict.
This is not a theoretical problem. It is why so many AI pilots perform beautifully in a controlled demo environment and then fall apart when exposed to real company data. The demo uses clean, consistent test data. The production environment has five years of accumulated inconsistencies.
The same dynamic plays out in customer service AI, financial reporting agents, HR workflow automation, and supply chain management. The technology is ready. The data often is not.
We also explored a related dimension of this in our article on why AI agents fail when your documentation lies. Documentation inconsistency and data inconsistency are two sides of the same problem.
Steps to Start Eliminating Conflicting Data in Your Organization
You do not need to rebuild your entire data infrastructure overnight. Here is a realistic starting point.
Start with a data audit. Map out where your most critical data lives. Customer records, product data, financial figures, and operational metrics. Identify where the same data exists in multiple places and flag any known discrepancies.
Assign data ownership. For each critical data type, designate one team or individual as the authoritative owner. They are responsible for accuracy and for resolving conflicts.
Establish a master data record. Pick one system as the source of truth for each data category. All other systems should sync from it, not maintain independent copies.
Build conflict resolution rules. When data discrepancies are detected, have a documented process for how they get resolved. This is especially important for AI systems, which need clear logic to follow rather than human judgment calls.
Test before you automate. Before deploying AI agents into any workflow, validate the data quality they will depend on. A short data quality assessment upfront saves weeks of troubleshooting later.
For organizations that are actively preparing for AI agent deployment, this aligns closely with the broader readiness framework we discuss in our guide on multiple versions of truth and why conflicting data kills your AI.
The Real Question Is: Are You Ready to Trust Your Own Data?
Here is an honest question worth sitting with. If your AI agent made a major business decision today based entirely on your current data, would you be comfortable with that?
If the answer is anything other than a clear yes, you have a data consistency problem worth addressing before you go any further with AI automation.
Multiple versions of truth are not just a technical issue. They are a trust issue. Your teams stop trusting reports because they have seen conflicting numbers too many times. Decisions slow down because nobody is confident in the baseline. And AI agents cannot step in to fix this because they rely on the same broken data to operate.
The companies that are getting real returns from AI right now have one thing in common. They sorted out their data foundations first. They did the unglamorous work of data governance, integration, and master data management before they went looking for the exciting AI use cases.
That is not a coincidence.
If you want to go deeper on what AI agents actually need from your data environment before they can operate reliably, our breakdown of why AI agents fail without real-time data access is a good next read. And if you are thinking about how approvals and review layers interact with your data quality problem, we have covered that too in our piece on AI agents and the missing approval layer.
Clean data is not the most exciting part of an AI strategy. But it is the part that determines whether the rest of it works.
Read More
Ysquare Technology
19/05/2026







