
Why Scattered Knowledge Is Killing Your AI Agent Implementation (And What to Do About It)

Your company just invested six figures in AI agents. The promise? Automated workflows, instant answers, lightning-fast decisions. The reality? Your agents keep giving wrong answers, missing critical information, and frustrating your team more than helping them.
Here’s the thing most people miss: It’s not the AI that’s failing. It’s your knowledge.
If your information lives across Slack threads, SharePoint sites, Google Docs, email chains, and someone’s desktop folder labeled “Important – Final – FINAL v2,” your AI agents don’t stand a chance. They can’t find what they need because you’ve built a knowledge maze, not a knowledge base.
Let’s be honest about what scattered knowledge really costs you — and more importantly, how to fix it before your AI investment becomes another failed tech initiative.
The Real Cost of Knowledge Chaos in the AI Era
When information sprawls across multiple tools and teams, it creates what experts call “knowledge silos.” Sounds technical. Feels expensive.
Companies lose between $2.4 million to $240 million annually in lost productivity due to knowledge silos, depending on their size and industry. That’s not a rounding error. That’s revenue you could be capturing.
But here’s where it gets worse for organizations deploying AI agents. Employees spend roughly 20% of their workweek — one full day — searching for information or asking colleagues for help. Now multiply that frustration by the speed at which AI agents need to operate.
Traditional employees at least know where to look when they hit a dead end. They know Sarah in Sales probably has that updated pricing deck, or that the engineering team keeps their documentation in Confluence (most of the time). AI agents don’t have that institutional memory. When they encounter scattered knowledge, they simply fail.
According to a 2025 McKinsey study, data silos cost businesses approximately $3.1 trillion annually in lost revenue and productivity. The shift to AI doesn’t solve this problem — it amplifies it.
Why AI Agents Demand Unified Knowledge (Not Just “Good Enough” Documentation)
Think about how your team currently finds information. Someone asks a question in Slack. Three people respond with slightly different answers. Someone else jumps in with “I think that process changed last month.” Eventually, someone digs up a document from 2023 that’s “probably still accurate.”
Humans can navigate this chaos. We read between the lines, verify with subject matter experts, and apply context based on what we know about the business. AI agents can’t do any of that.
When an agent gives the wrong answer, the correct information often exists somewhere in your organization — scattered across SharePoint, Confluence, email chains, and tribal knowledge — but your agent simply can’t find it.
Here’s what makes scattered knowledge particularly destructive for AI implementations:
Information lives in isolation. Your customer service knowledge base hasn’t been updated with the product changes engineering shipped last quarter. Your sales playbook doesn’t reflect the pricing structure finance approved two weeks ago. Each team operates with their own version of truth, and your AI agent has to pick which one to believe.
Unstructured knowledge limits accuracy. AI agents need clean, organized, validated information to function properly. When your knowledge exists as casual Slack conversations, outdated PDFs, and half-finished wiki pages, the fragmentation combined with limitations of manual knowledge capture and organization often results in decreased productivity and missed opportunities for innovation.
Context gets lost. A document sitting in a folder tells an AI agent nothing about whether it’s current, who approved it, or if it’s been superseded by newer information. Unlike structured data which is well organized and more easily processed by AI tools, the sprawling and unverified nature of unstructured data poses tricky problems for agentic tool development.
The “Single Source of Truth” Myth That’s Holding You Back
Every organization says they want a single source of truth. Almost none have one.
What most companies actually have is a “preferred source of truth” (the official wiki that nobody updates) and a “working source of truth” (the Slack channel where real work gets discussed). AI agents need the latter, but they only get trained on the former.
Shared understanding among AI agents could quickly become shared misconception without ongoing maintenance. If you’re feeding your agents outdated documentation while your team operates based on recent conversations and tribal knowledge, you’re setting them up to confidently deliver wrong answers.
The real question isn’t “Where should we centralize everything?” The real question is “How do we keep knowledge current, connected, and contextual across all the places it naturally lives?”
What Good Knowledge Management Actually Looks Like for AI Agents
Companies that successfully deploy AI agents don’t necessarily have less knowledge. They have better-organized knowledge with clear ownership and maintenance processes.
Here’s what separates organizations ready for AI from those still struggling:
Clear ownership of every knowledge asset. Someone owns each piece of information — not just the creation, but the ongoing accuracy. When a product feature changes, there’s a person responsible for updating that knowledge across all relevant systems. No orphaned documents. No “I think someone was supposed to update that.”
Connected information architecture. Your pricing information should automatically flow to sales training materials, customer service scripts, and product documentation. Research shows that sharing knowledge improves productivity by 35%, and employees typically spend 20% of the working week searching for information necessary to their jobs. Connected systems cut that search time dramatically.
Version control that actually works. One of the more significant challenges is identifying the latest, accurate versions to include in AI models, retrieval-augmented generation systems, and AI agents. If your agent can’t tell which version of a document is current, it will default to whatever it finds first — which is often wrong.
Metadata that tells the story. Every document should answer: Who created this? When? Who approved it? When was it last verified? What’s the review schedule? Is this still current? External unstructured data requires thoughtful data engineering to extract and maintain structured metadata such as creation dates, categories, severity levels, and service types.
Active curation, not passive storage. Knowledge curation transforms scattered information into agent-ready intelligence by systematically selecting, prioritizing, and unifying sources. This isn’t a one-time migration project. It’s an ongoing practice of keeping your knowledge ecosystem healthy.
The Hidden Knowledge Gaps That Break AI Agents
Even when organizations think they’ve centralized their knowledge, critical gaps remain. These gaps don’t show up in a content audit, but they destroy AI agent performance:
The expertise that lives in people’s heads. Your senior account manager knows that Enterprise clients get special payment terms, but that’s not documented anywhere. Your lead engineer knows that certain API endpoints are unstable under specific conditions, but the official docs don’t mention it. This tribal knowledge is invisible to AI agents until they fail because of it.
Process knowledge versus documented process. Your official onboarding process says new hires complete training in two weeks. The reality? Managers always extend it to three weeks because two isn’t realistic. When documented processes don’t reflect how work actually happens, the gap leads to incorrect decisions. AI agents trained on official documentation will give answers based on the fantasy version of your processes.
The context that makes information actionable. A discount code might be technically active, but customer service shouldn’t offer it because it’s reserved for churn prevention. A feature might be live, but sales shouldn’t mention it because it’s not ready for general availability. The information alone isn’t enough — AI agents need the context around when and how to use it.
Cross-functional dependencies nobody documented. Marketing launches a campaign that Sales wasn’t looped into. Engineering deprecates an API that Customer Success was using in their workflows. When Team A needs information from Team B to complete their work, but that knowledge stays locked away, projects stall. AI agents can’t navigate these dependencies if they’re not mapped.
How to Audit Your Knowledge Readiness for AI Agents

Before you invest another dollar in AI implementation, run this diagnostic. It will tell you whether your knowledge infrastructure can actually support autonomous agents:
The “new hire test.” Could a brand new employee find the answer to a routine customer question using only your documented knowledge base? If they’d need to ask three people and dig through Slack history, your AI agent will fail too.
The “conflicting information test.” Search for your return policy across all your systems. How many different versions do you find? If the answer is more than one, your knowledge is fragmented. When different files, tools, and teams create conflicting data, agents struggle when there’s no single reliable source.
The “knowledge owner test.” Pick ten critical documents. Can you identify who owns each one? Who updates them when things change? If the answer is “whoever created it three years ago but they left the company,” you have an ownership problem.
The “last updated test.” Look at your top 20 most-accessed knowledge articles. When were they last reviewed? Anyone who has stumbled across an old SharePoint site or outdated shared folder knows how quickly documentation can fall out of date and become inaccurate. Humans can spot these red flags. AI agents can’t.
The “retrieval test.” Ask five people across different departments to find the same piece of information. How many different places do they look? How long does it take? If everyone has a different search strategy, your knowledge isn’t as organized as you think.
Building an AI-Ready Knowledge Foundation: The Practical Path Forward
Here’s what most consultants won’t tell you: You don’t need to fix everything before deploying AI agents. You need to fix the right things in the right order.
Start with your highest-impact knowledge domains. Where do wrong answers cost you the most? Customer service? Sales enablement? Technical support? Start there. Apply impact filters prioritizing sources that drive revenue, reduce risk, or unblock high-volume tasks. A pricing database enabling deal closure ranks higher than archived meeting notes.
Create a knowledge governance model. Assign clear owners. Establish review cycles. Build update workflows. Unlike traditional knowledge management systems, context-aware AI considers the user role, workflow stage, and policy requirements. Your governance model should support this by ensuring the right information gets to the right agents at the right time.
Connect your knowledge sources, don’t consolidate them. You don’t need to move everything into one system. You need systems that talk to each other. The real value comes from converting fragmented information into contextual, workflow-ready intelligence — not just faster retrieval.
Implement structured metadata. Add consistent tags, categories, and attributes to your knowledge assets. This metadata helps AI agents understand not just what information says, but when it’s relevant, who should use it, and how current it is.
Build feedback loops. Discovery tools should profile content and enable training on your historical data. When your AI agent gives a wrong answer, that should trigger a knowledge review. Wrong answers are symptoms of knowledge gaps — treat them as diagnostic tools.
Invest in knowledge curation, not just content creation. Most organizations have enough knowledge. They don’t have enough organized, validated, accessible knowledge. The key discovery question cuts through organizational assumptions: “When an agent gives the wrong answer, where would a human expert double-check?” This reveals gaps between official documentation and working knowledge.
The Questions Leaders Should Be Asking (But Usually Aren’t)
If you’re a CEO, CTO, or business leader evaluating AI agent readiness, stop asking “What’s the best AI platform?” Start asking these questions instead:
- Can we confidently point to a single authoritative answer for our top 100 business questions?
- When critical information changes, how long does it take to update across all relevant systems?
- If our AI agent answers a customer question incorrectly, could we trace back to why?
- Do we have governance processes for knowledge creation, review, and retirement?
- What percentage of our organizational knowledge exists only in employee heads or informal channels?
The answers to these questions determine whether your AI investment delivers value or becomes another expensive failed experiment.
What Success Actually Looks Like
Organizations that nail knowledge management for AI agents don’t have perfect documentation. They have living, maintained, connected knowledge ecosystems.
AI agents are helping organizations rethink how they capture, organize, and tap into their collective knowledge — acting more like intelligent coworkers able to understand, reason, and take action.
But this only works when the knowledge foundation is solid. When information flows freely across systems. When ownership is clear. When currency is tracked. When context is preserved.
The companies seeing real ROI from AI agents didn’t start with the sexiest AI models. They started by fixing their knowledge infrastructure. They recognized that organizations need trusted, company-specific data for agentic AI to truly create value — the unstructured data inside emails, documents, presentations, and videos.
The Bottom Line
Your AI agents are only as good as the knowledge they can access. Scattered, siloed, outdated information doesn’t become magically useful just because you’ve deployed advanced AI models.
The gap between AI hype and AI reality isn’t about the technology. It’s about the foundation. Companies rushing to implement AI agents without fixing their knowledge infrastructure are building on quicksand.
The good news? Knowledge management is solvable. It’s not a sexy transformation project, but it’s the difference between AI agents that actually work and ones that just frustrate your team.
The question isn’t whether you should fix your scattered knowledge problem. The question is whether you’ll fix it before or after your AI initiative fails.
Frequently Asked Questions
1. What is scattered knowledge in an organization?
Scattered knowledge refers to critical business information that's fragmented across multiple tools, teams, and systems — including Slack, email, SharePoint, Google Docs, and tribal knowledge. Instead of having a unified, accessible knowledge base, information exists in silos that are difficult to find, verify, and keep current. This fragmentation costs companies between $2.4 million to $240 million annually in lost productivity, depending on organization size.
2. Why do AI agents fail when knowledge is scattered?
AI agents need clean, organized, validated information to function accurately. When knowledge is scattered across disconnected systems, agents can't determine which information is current, authoritative, or contextually relevant. Unlike humans who can verify information with subject matter experts or apply institutional knowledge, AI agents simply return incomplete or incorrect answers when they encounter fragmented data sources.
3. How much does scattered knowledge cost businesses?
According to 2025 research, data silos cost businesses approximately $3.1 trillion annually in lost revenue and productivity globally. Individual companies lose between $2.4 million to $240 million per year depending on size and industry. Additionally, employees spend 20% of their workweek (one full day) searching for information or asking colleagues for help — time that could be spent on revenue-generating activities.
4. What is the difference between scattered knowledge and knowledge silos?
The terms are closely related but slightly different. Knowledge silos occur when specific departments or teams hoard information without sharing it across the organization. Scattered knowledge is broader — it refers to any situation where information exists in multiple disconnected locations, regardless of whether teams are deliberately keeping it siloed. Both create the same problem for AI agents: inability to access complete, accurate information.
5. How can I tell if my organization has a scattered knowledge problem?
Run the "new hire test": Could a brand new employee find answers to routine questions using only your documented knowledge base? If they need to ask multiple people and dig through chat history, you have scattered knowledge. Other warning signs include: conflicting information across systems, no clear ownership of documents, outdated content that hasn't been reviewed in months, and employees using different search strategies to find the same information.
6. What is knowledge curation and why does it matter for AI?
Knowledge curation is the systematic process of selecting, prioritizing, organizing, and unifying scattered information sources to create agent-ready intelligence. Unlike passive content storage, curation involves ongoing maintenance, validation, and connection of knowledge assets. For AI agents, proper curation means the difference between accessing fragmented, unreliable data and having a clean, contextual knowledge foundation that enables accurate responses.
7. Do I need to centralize all knowledge into one system for AI agents?
No. While centralization sounds ideal, it's often impractical and can create new problems. Instead, focus on connecting your knowledge sources so they can communicate with each other. The goal is interoperability and consistent metadata across systems — not forcing everything into a single platform. Modern AI-ready knowledge architectures allow information to live in appropriate systems while maintaining connections and ensuring agents can access what they need.
8. How does unstructured data affect AI agent accuracy?
Unstructured data (emails, documents, presentations, videos) makes up 80-90% of enterprise information but is much harder for AI agents to process than structured data (databases, spreadsheets). When unstructured data lacks metadata, version control, and clear ownership, AI agents struggle to determine which information is current, relevant, and authoritative. This challenge is why organizations with better-organized unstructured data see 40% higher AI accuracy according to IBM testing.
9. What is the single source of truth and why is it important for AI?
A single source of truth (SSOT) means having one authoritative, up-to-date version of each piece of business information. In reality, most companies have a "preferred source of truth" (official documentation nobody updates) and a "working source of truth" (Slack conversations where real decisions happen). AI agents trained on the official version will give answers that don't reflect how work actually gets done, leading to frustrated users and failed implementations.
10. How long does it take to fix scattered knowledge for AI readiness?
There's no universal timeline — it depends on your organization's size, complexity, and current state. However, you don't need to fix everything before deploying AI agents. Start with your highest-impact knowledge domains (areas where wrong answers cost the most), implement governance and ownership, and build from there. Most organizations see meaningful progress within 3-6 months when they prioritize knowledge curation systematically rather than attempting complete centralization overnight.

No Clear AI Ownership: The Silent Reason Your AI Agents Keep Breaking Down
Your AI agent goes live. It works. Then three weeks later, something quietly goes wrong. Outputs start drifting. A workflow sends the wrong notification. A report pulls stale data. And when you ask who is responsible for fixing it, everyone looks at someone else.
That is not a technology problem. That is an ownership problem.
No clear AI ownership in organizations is one of the most overlooked readiness gaps in enterprise AI today. You can build the most sophisticated agent in the world, but if nobody is accountable for its outcomes, it will fail. Slowly. Quietly. Expensively. This piece is part of our AI Agent Readiness Series, and it addresses Sign 11 from the framework: No Clear Ownership. If you have been nodding along to other signs in this series, like scattered knowledge silently sabotaging your AI or multiple versions of truth killing your data decisions, this one will hit close to home.
What Does No Clear AI Ownership Actually Mean?
Let’s be honest. Most companies deploy AI agents with a lot of excitement and very little clarity on who owns what after go-live.
No clear AI ownership means there is no single person or team formally accountable for an AI agent’s performance, outputs, or continuous improvement. It is not about who built it or who approved the budget. It is about who wakes up at 7 AM when the agent starts sending customers the wrong information.
Here is what this typically looks like in practice:
- The IT team says it is a business problem once it is deployed.
- The business team says it is a technical issue when something breaks.
- The vendor says it is working as intended.
- Leadership is waiting for a report that nobody is writing.
When issues remain unresolved because nobody is responsible for AI outcomes, the damage compounds every single day. That is the real cost of unclear accountability.
It connects directly to other readiness gaps too. If your documentation does not reflect how work actually happens, then your AI agent is working from a broken map. And if nobody owns the agent, nobody updates that map either.
Why AI Accountability in Business Is Not Optional
There is a phrase that applies perfectly here: ownership drives accountability. Without it, you do not have AI-assisted operations. You have AI-assisted chaos with better branding.
Think about what happens when an AI agent makes a wrong decision without a defined owner to catch it. If nobody validates outputs, mistakes can scale quickly. That is not a theoretical concern. In B2B environments where agents handle customer communications, data routing, or financial approvals, a single undetected error can trigger a cascade.
We covered the approval problem in depth in our piece on AI agents failing without an approval or review layer. But even a well-designed approval layer falls apart when no one is accountable for reviewing the reviews.
The real question is not whether your AI agent will ever make a mistake. It will. Every system does. The question is whether you have someone positioned to catch it, correct it, and prevent it from happening again. That person needs a title, a mandate, and the authority to act.
Primary keyword note: AI accountability in business is not a governance checkbox. It is the operating system that keeps your AI investments producing returns instead of producing liability.
The Real Cost of Undefined AI Accountability in Enterprise Teams
Let’s talk about what this actually costs you. Not in abstract terms but in operational reality.
1. Performance Degrades Without Anyone Noticing
AI agents are not static. Business context changes. Data sources evolve. Customer behavior shifts. Without an owner monitoring performance metrics, your agent keeps running on logic that was accurate six months ago and is quietly wrong today.
This connects directly to the measurement gap. When you are not tracking metrics for AI performance, you have no way to detect that your AI is underperforming until the damage is already done. Ownership without measurement is blind. Measurement without ownership is pointless.
2. Nobody Iterates. Performance Stagnates.
AI systems improve with feedback. That is not a nice-to-have. That is how they work. Without post-launch iteration driven by a named owner, your agent reaches a performance ceiling on day one and stays there.
We wrote about this specifically in the context of no post-launch iteration being a critical AI readiness gap. Without someone accountable for ongoing improvement, the agent becomes a legacy system the moment it goes live.
3. Conflicts Get Kicked Upstairs or Ignored
When your AI agent produces conflicting outputs across departments, someone needs the authority to resolve those conflicts. Without a defined owner, those conflicts sit in email threads and Slack messages for weeks. Meanwhile, the agent keeps producing wrong outputs at scale.
4. Security Gaps Go Unaddressed
An AI agent operates differently from a human employee. It does not get tired, distracted, or hesitant. When it has access to sensitive systems and nobody owns it, the access permissions set at launch never get reviewed. We explored this in our piece on security systems built only for humans failing AI agents. The ownership gap and the security gap feed each other.
What Good AI Ownership Structure Looks Like
Good AI ownership is not about adding another title to your org chart. It is about clarity. Here is what a functional ownership model looks like in practice.
Name One Person Per Agent
Every deployed AI agent should have exactly one named owner. Not a committee. Not a shared inbox. One person who is accountable for its performance, its outputs, and its ongoing improvement. That person should be close enough to the business process to understand context and senior enough to make decisions without escalating every change.
Define the Scope of Ownership
Ownership without scope creates confusion. Your AI owner needs to know exactly what they are responsible for. That includes performance benchmarks, error thresholds, data quality standards, and escalation paths when something breaks down.
This connects to the broader problem of real-time data access being a hidden readiness gap. An AI owner needs to know whether the agent is accessing live signals or stale data. That is a scope question before it becomes a technical question.
Build In Review Cycles
An AI agent should have a monthly or quarterly performance review the same way a business unit does. The owner leads this review, brings in the right stakeholders, and makes the call on what needs to change. Without structured review cycles, ownership is just a label.
Connect Ownership to Leadership Buy-in
Here is the catch. Ownership only works when leadership actually supports it. If the C-suite treats AI agents as a one-time deployment instead of a living system, your AI owner will be fighting a constant uphill battle. We covered this in our piece on leadership not driving AI adoption as a critical readiness failure. Adoption starts at the top. So does accountability.
How No Clear Ownership Connects to Other AI Readiness Gaps
Ownership is not an isolated problem. It sits at the intersection of almost every other AI readiness gap.
When you have multiple versions of truth creating conflicting data, an AI owner is the person who decides which version the agent trusts. Without that owner, the agent picks arbitrarily and nobody questions it.
When your documentation does not match how work actually happens, the owner is the person who ensures the agent is updated to reflect real processes, not documented ones.
When real-time data access is blocked or incomplete, the owner escalates that dependency and ensures the agent is not making decisions on outdated signals.
And when knowledge is scattered across silos and tools, the owner maps those silos and ensures the agent knows where to look.
The AI owner is, in effect, the connective tissue between your AI investment and the real business it is supposed to serve.
Steps to Fix the AI Ownership Gap Starting This Week
You do not need a six-month governance program to fix this. You need a few clear decisions made this week.
- Audit your deployed agents. List every AI system currently running in your organization. For each one, write down one name next to it. That person is the interim owner starting today.
- Define what ownership means. Create a one-page ownership charter per agent. Include performance KPIs, review frequency, escalation contacts, and change authority.
- Get a leadership sponsor. Every AI owner needs a leadership sponsor who will remove blockers and ensure the ownership role is respected cross-functionally.
- Set a 90-day review. Within 90 days of assigning an owner, conduct a formal performance review of the agent. This creates the first feedback loop and tests whether ownership is working.
- Tie ownership to outcomes. The AI owner should be measured on the outcomes the agent is supposed to deliver, not on whether the agent is running. Running is not the same as performing.
Is Your Organization Ready to Own Its AI Agents?
Most organizations are not. That is not a criticism. It is just the reality of where enterprise AI adoption is right now. The technology has moved faster than the organizational structures needed to govern it.
The good news is that this is one of the most solvable readiness gaps. It does not require new technology. It does not require a massive budget. It requires a decision: who owns this?
Make that decision for every AI agent you currently have running. Then make it mandatory before every future deployment. It sounds simple because it is. The complexity is in building the organizational culture where ownership is respected, supported, and measured.
If you are serious about AI agent readiness, start with our full readiness framework on the Ysquare Technology LinkedIn page. Each sign in the series connects to the others, and ownership is the thread that runs through all of them.
Final Thought: Ownership Is Not Bureaucracy. It Is How AI Scales.
Every time an AI agent fails quietly in a corner of your organization, it erodes trust in AI as a whole. Teams stop using it. Leadership pulls funding. The technology gets blamed when the problem was always structural.
Defining clear AI ownership is how you prevent that. It is how you build AI that improves month over month instead of decaying from launch day. It is how you turn a one-time deployment into a competitive advantage that compounds over time.
The question is not whether your AI can do the job. The question is whether your organization is structured to support it. Start with ownership. Everything else gets easier from there. And if you want a full picture of where your AI readiness stands today, explore our growing series covering all 15 signs, beginning with how scattered knowledge blocks AI agent performance.
Read More

Ysquare Technology
09/06/2026

No Post-Launch Iteration: The Silent Reason Your AI Agents Stop Improving
You spent months building your AI agent. The demo worked beautifully. Leadership approved the rollout. And then you launched. That was six months ago. Here is the question nobody in your organization is asking: is that agent actually getting better?
Most of the time, the honest answer is no. Not because the technology failed, but because the team moved on. There is a deeply ingrained assumption in enterprise AI deployments that launch is the finish line. It is not. Launch is where the real work begins. And skipping the post-launch iteration phase is one of the most expensive mistakes organizations make with AI agents today.
This is part of a broader pattern we have been tracking across enterprise AI readiness. If you have already read about how scattered knowledge silently sabotages your AI agents, you will recognize the theme: the problems that kill AI agent performance are rarely about the model itself. They are, instead, about the organizational infrastructure around it. And no post-launch iteration is one of the most overlooked gaps of all.
The Production Reality
The Composio AI Agent Report 2025 found that 67% of organizations report measurable gains from agent pilots, yet only 10% successfully scale to production. The gap does not sit in the technology. It lives, instead, in what happens, or more accurately what does not happen, after the agent goes live.
What No Post-Launch Iteration Actually Means for Your AI Agents
Let us be clear about what we are talking about. Post-launch iteration for AI agents is the ongoing process of monitoring real-world performance, collecting feedback, identifying failure patterns, and making targeted improvements. In other words, it is the cycle that turns a static deployment into a system that learns and compounds value over time.
Without it, your AI agent becomes frozen at the capability level it had on launch day. That is a serious problem, because the world around it does not stay frozen. Business processes shift, data patterns change, user needs evolve, and edge cases multiply. As a result, what performed well in testing starts encountering situations it was never prepared for in production.
The degradation is rarely dramatic, which is precisely what makes it so dangerous. A real-world case documented by SaaStr describes a team that deployed an AI agent, watched it perform well, and then moved on to other projects. Four months later, the agent had quietly stopped ingesting new data. Moreover, it kept running and kept producing outputs that looked plausible, but was operating entirely on stale information. The team only caught it when results started feeling slightly off. Not wrong enough to trigger alarms. Just a little out of step with reality.
This is the operational signature of an AI agent with no iteration loop. Rather than crashing visibly, it just slowly stops being useful.
Furthermore, the same dynamic is explored in depth in our LinkedIn article on why post-launch iteration is the silent reason your AI agents underperform, which looks at how this pattern shows up across enterprise deployments of every size.
Why AI Agent Performance Stagnation Is Now a Business Risk
The scale of the problem is becoming impossible to ignore. According to a June 2025 Gartner press release, over 40% of agentic AI projects will be canceled by the end of 2027, with escalating costs, unclear business value, and inadequate risk controls as the primary reasons. What does inadequate risk control look like in practice? Often it looks exactly like an agent running in production with no feedback loop and no mechanism for improvement.
McKinsey’s 2025 State of AI report reinforces the picture: fewer than 20% of AI pilots scale to production within 18 months, and only 39% of organizations report any enterprise-level EBIT impact from AI. Consequently, the organizations that are generating real returns are not necessarily the ones with the best models. They are the ones that have built processes for continuous improvement after launch.
Beyond that, research from Lemma, a YCombinator F25 company building continuous learning infrastructure for AI agents, found that agent performance can drop approximately 40% within weeks of deployment. This happens as real-world input drift introduces user behaviors and edge cases that were not present in testing. That is not a model failure. That is a process failure, and it is entirely preventable with the right iteration infrastructure in place.
The Compounding Cost
High-volume agents processing thousands of transactions daily see measurable accuracy improvements within 30 to 45 days when a feedback loop is active. Without one, however, performance flatlines or silently degrades from day one. The longer you wait to implement iteration, the more ground you have to recover.
The Five Ways No Post-Launch Iteration Damages AI Agent Readiness
Understanding the specific mechanisms of performance stagnation helps you make the case internally for why iteration infrastructure is not optional. Here are the five most common patterns we see.
1. Distribution Shift Goes Undetected
Your agent was trained and tested on a specific snapshot of your business data. The moment it goes live, however, the real world starts diverging from that snapshot. New product lines, updated workflows, seasonal demand shifts, and new customer segments all push the agent away from its original frame of reference. Distribution shift is the technical term for this divergence, and without continuous monitoring, it remains invisible until the agent starts making decisions that feel wrong but are hard to explain.
The connection to your broader data environment is critical here. If your organization already struggles with multiple versions of truth creating conflicting data across systems, distribution shift compounds that problem at speed.
2. Edge Cases Accumulate Without Resolution
No pre-launch test suite captures every real-world scenario. Edge cases are inevitable, and therefore the question is not whether your agent will encounter them but whether your organization has a mechanism for identifying, analyzing, and resolving them. Without an iteration process, those edge cases pile up and are never addressed. Each one represents a user who received a wrong or unhelpful response. At scale, this erodes trust in ways that are very difficult to recover from.
3. Business Process Changes Outpace the Agent
Organizations are not static. Processes change, policies update, and teams restructure constantly. As a result, an AI agent trained on how your business operated six months ago becomes increasingly misaligned with how it operates today. This is especially dangerous when the agent is handling workflows that touch customers, finance, or compliance. We have covered the upstream version of this problem in our piece on undocumented workflows and AI automation failures. The same dynamic plays out post-launch when iteration is absent.
4. No Feedback Means No Learning Signal
Research from Dust’s continuous improvement framework is clear on this point: if there is no clear owner for an agent and no time allocated to iterate, agents simply do not improve. Feedback that is never collected cannot drive learning. In addition, many organizations have no structured process for gathering input from the people who interact with the agent every day, whether they are employees or customers.
Because of this, organizations that have no system for measuring AI agent performance after deployment are essentially operating blind. You cannot improve what you are not measuring.
5. Security and Compliance Drift
An agent that handled sensitive data appropriately at launch may not remain compliant as regulations evolve and your data environment changes. Security models built for static systems need regular review when applied to autonomous agents. This is not theoretical: the AI Incidents Database reports that AI-related incidents rose 21% from 2024 to 2025. Furthermore, many of those incidents involve agents that were operating outside their original governance parameters without anyone noticing.
For a detailed look at why security frameworks designed for human operators fail AI agents, our blog post on security models built only for humans creating AI agent vulnerabilities covers the specific gaps that post-launch monitoring needs to close.
How Post-Launch Iteration Actually Works in Practice
Here is the thing: building an iteration loop for your AI agent does not require a separate engineering team or a six-month project. It requires clarity about four things.
Continuous Monitoring with Automated Evaluation
You need a system that scores agent responses against accuracy, helpfulness, and task completion on an ongoing basis, not just in pre-launch testing. Leading evaluation frameworks now support LLM-as-a-judge scoring, where a secondary model reviews a sample of production outputs and generates quality scores. Performance is graphed over time, and alerts fire when quality degrades. As a result, you find out from a dashboard rather than from an angry user or a manager who noticed something felt off.
Structured Feedback Collection from Real Users
The people using your agent every day are your best source of iteration signal. Building a lightweight, structured mechanism for them to flag unhelpful or incorrect responses turns anecdotal frustration into actionable data. Fortunately, the feedback does not need to be complex. A simple thumbs-down with a category tag is enough to surface patterns.
Beyond flagging errors, your approval and review layer for AI outputs becomes a source of iteration data, not just a quality gate. Every human review generates a signal about where the agent’s judgment diverged from the expected outcome.
Targeted, Incremental Updates
The most common mistake in post-launch iteration is trying to overhaul the agent when a targeted edit would suffice. The Dust framework recommends starting with the top failure mode surfaced by your monitoring, making a surgical change to instructions, data sources, or parameters, testing with a small group, and then rolling out broadly. Small, targeted changes are easier to test and, equally important, easier to roll back if something breaks.
This is the iteration mentality that software engineering teams have applied for decades. AI agents deserve the same discipline. Ship, measure, learn, and improve. Then repeat.
Ownership and Accountability
No iteration loop survives without a named owner. Someone in your organization needs to be responsible for the agent’s ongoing performance, with time explicitly allocated to the iteration process. Without this structure, feedback goes nowhere and insights gather dust. This gap is directly linked to the leadership ownership gap that keeps AI agents underperforming across enterprises, a pattern our piece on leadership not driving AI adoption examines from the top down.
What Your AI Agent Ecosystem Looks Like Without Iteration
Let us paint the picture honestly. Six months after launch, an AI agent with no iteration process typically looks like this:
- Performance has plateaued or quietly declined from its peak at launch
- Users have developed workarounds for the edge cases the agent handles poorly
- Business process changes have introduced misalignments the agent has no way to know about
- The team that built the agent has moved on to the next project
- Nobody has a clear picture of what the agent is actually doing at scale
This is not a hypothetical. It is the operational reality for a significant portion of enterprise AI deployments today. The Composio 2025 report’s finding that only 10% of organizations successfully scale agent pilots to production reflects both a pre-launch problem and a post-launch one. Many organizations reach production and then fail to sustain it because there is no iteration infrastructure keeping the agent aligned with reality.
The data quality dimension makes this even more acute. If your agent is operating on real-time data access gaps that leave it working from outdated information, the absence of post-launch iteration means those gaps compound rather than get resolved. Consequently, the agent becomes increasingly disconnected from the current state of your business.
Building the Case for Post-Launch Iteration Internally
If you are a technology leader reading this, you likely already know the iteration gap exists in your organization. The challenge, however, is making the case for dedicated iteration resources in an environment where the initial deployment already consumed significant budget and attention.
Frame It as a Cost of Stagnation, Not a Cost of Iteration
Here is the framing that tends to land with business stakeholders. Your AI agent is a revenue or efficiency-linked system. Its current performance level represents a baseline, and therefore every week you do not iterate is a week you are leaving potential improvement on the table. Every edge case that accumulates represents a customer interaction or process step where the agent is actively failing. The cost of not iterating is not zero. It is the cumulative sum of all those missed improvements and unresolved failures.
Anchor to ROI Evidence
McKinsey data shows that organizations achieving real ROI from AI are not necessarily using better models. Instead, they are applying better operational discipline to the systems they have. The 5.8x ROI on AI investment within 14 months that McKinsey’s research documents is not achieved by deploying and forgetting. It is achieved by deploying, measuring, iterating, and compounding gains over time.
Include Documentation Teams in the Conversation
Beyond the commercial case, the technical teams building documentation for your agent also need to be part of this discussion. If your documentation does not reflect how AI agents actually make decisions in the field, iteration becomes much harder because you have no reliable baseline to measure against.
Practical Steps to Start Your Post-Launch Iteration Process Today
You do not need to wait for a perfect system. You need to start. Here is a practical sequence that works for organizations at every stage of AI maturity.
Step 1: Assign an Agent Owner
Name a single person responsible for the ongoing performance of each production AI agent. While this does not need to be a full-time role, it needs to be a named accountability. Without ownership, everything else in this list will fail to stick.
Step 2: Define Your Performance Baseline
Before you can track improvement, you need to know where you are starting. Pull your current task completion rates, user satisfaction signals, and error patterns. If you do not have this data yet, the first iteration sprint should focus on instrumentation: getting the logging and monitoring in place so you have something to measure against.
Step 3: Run a Weekly Feedback Review
Set a recurring thirty-minute review where the agent owner looks at the feedback and error data from the previous week. Identify the top failure pattern. Then make one targeted improvement, not a full rebuild. Test it, observe the impact, and repeat next week.
Step 4: Connect Your Iteration Loop to Your Data Infrastructure
The iteration process only works if the agent is operating on accurate, current data. If scattered knowledge across your organization is limiting what your AI agents can access, your iteration loop needs to include data quality improvements, not just prompt tuning.
Step 5: Make Iteration Part of Your AI Governance Framework
Finally, post-launch iteration should not be an informal practice that depends on individual initiative. It should be a documented process with scheduled reviews, defined metrics, and governance sign-off for significant changes. This is what turns a good AI deployment into a sustainable one.
The Real Question Is Not Whether to Iterate. It Is How Long You Can Afford Not To.
Here is a perspective shift worth sitting with. Every enterprise software system your organization depends on gets maintained, updated, and improved on a regular cycle. Nobody deploys a CRM or an ERP and then never touches it again. Yet that is exactly the treatment many organizations give their AI agents, and then they wonder why the results plateau.
AI agents are not set-and-forget tools. They are living systems that operate in changing environments and need ongoing attention to stay aligned with your business reality. Therefore, the organizations that will generate lasting ROI from AI are the ones building the discipline of continuous iteration into their deployment model from day one.
Gartner’s warning that over 40% of agentic AI projects will be canceled by end of 2027 is not a verdict on AI technology. Rather, it is a verdict on AI deployment practices. The technology works. The processes around it are, however, still catching up. Post-launch iteration is one of the places where closing that gap makes the most immediate difference.
If you are building AI agents at scale and want to make sure iteration is built into your readiness model from the ground up, connect with the Ysquare Technology team on LinkedIn to explore how we approach enterprise AI agent deployment with long-term performance in mind.
Read More
Ysquare Technology
05/06/2026

Why Leadership Must Drive AI Agent Adoption Across the Organization
Here is a question worth sitting with: Your company just spent six figures on AI tools. Your IT team built the pilots. Your vendor gave three onboarding sessions. And yet, six months in, adoption across the organization is hovering somewhere between “low” and “invisible.”
Sound familiar?
This is not a technology problem. It is not a budget problem. And it is definitely not a problem your IT team can fix on their own.
When leadership isn’t driving AI adoption, everything else you do to push it forward is just noise. Teams take their cues from the top. If they don’t see their managers, directors, and executives actively using AI, talking about AI, and holding people accountable to AI outcomes, then AI becomes just another initiative that will quietly fade away after the next quarterly review.
The data backs this up. McKinsey’s 2025 Workplace AI report surveyed 3,613 employees and 238 C-level executives and found that employees are ready for AI, but leaders are not steering fast enough. The biggest barrier to success is leadership.
That is not a small finding. That is the finding. And if you’re a CEO, CTO, or senior business leader, this one is squarely on your desk.
Why Leadership Isn’t Driving AI Adoption Is the Real Bottleneck
Most organizations frame AI adoption as a rollout problem. They build a roadmap, pick a vendor, set up training sessions, and wait for adoption to happen. It doesn’t. Because adoption isn’t a rollout problem. It’s a culture problem, and culture is set by leaders.
Think about how any new behavior spreads inside a company. People don’t change how they work because they attended a webinar. They change because they see their peers doing things differently, because their manager asks them different questions, and because their performance is measured against different outcomes. None of that happens without leadership actively driving it.
When executives treat AI as someone else’s responsibility, a few predictable things occur. Teams see AI as optional. Middle managers don’t prioritize it. Budgets get questioned at renewal time. And the early adopters who were genuinely excited burn out trying to evangelize uphill without any support.
McKinsey’s research shows that AI high performers are three times more likely to have senior leaders who demonstrate ownership of and commitment to their AI initiatives. Those same leaders actively use AI themselves and role-model the behavior they want to see across the organization.
That three-times multiplier isn’t marginal. It’s the difference between companies that are genuinely transforming and companies that are running expensive pilots forever.
What the Numbers Actually Say About Leadership and AI Success

The statistics here are sobering, and leaders need to face them honestly.
According to McKinsey’s 2025 State of AI report, 88% of organizations reported regular AI use in at least one business function in 2025, compared with 78% a year earlier. But only about one-third have begun scaling AI programs across the organization. The gap between “we’re using AI somewhere” and “AI is changing how we operate” is enormous, and leadership behavior sits right in the middle of it.
A 2025 report from WRITER, which surveyed 1,600 knowledge workers including 800 C-suite executives, found that more than one in three executives describe their generative AI adoption as a “massive disappointment.” Two-thirds of C-suite leaders reported tension between IT teams and other business units around AI implementation.
Here’s the number that should alarm every board room: Only 28% of organizations report that their CEO takes direct responsibility for AI governance and oversight. Yet the companies where the CEO is directly involved in AI governance report meaningfully higher business impact from their AI investments.
The math is simple. When the CEO owns it, it gets resourced, prioritized, and measured. When AI is delegated to a single team, it gets stuck.
McKinsey’s March 2025 report, “How Organizations Are Rewiring to Capture Value,” reinforces this directly: only 28% of respondents whose organizations use AI say their CEO oversees AI governance, and CEO oversight is strongly correlated with higher self-reported bottom-line impact.
The IBM Watson Story: A Masterclass in What Happens Without Real Governance
No case study on AI adoption failure is more instructive than the story of IBM Watson for Oncology.
IBM positioned Watson Health as a moonshot. The technology would democratize elite oncology expertise, helping clinicians around the world make better cancer treatment decisions. IBM committed billions of dollars. The marketing was confident. The promise was enormous.
What actually happened was a governance and leadership failure at scale.
The system was developed with training data curated by a small group of physicians using hypothetical patient cases, not real clinical data. When hospitals tried to deploy it in the real world, the recommendations were often inconsistent with national treatment guidelines. One physician at a Florida hospital told IBM executives the system was “worthless” for most cases, and that the hospital had bought it largely for marketing purposes.
When MD Anderson Cancer Center, one of Watson’s most prominent partners, transitioned from its legacy EHR system to Epic Systems, Watson couldn’t access live patient data. A $62 million investment became, in the words of one review, a “custom demo.”
By 2022, IBM announced the sale of Watson Health’s healthcare data and analytics assets to Francisco Partners. Financial terms were not officially disclosed, though reports placed the deal at more than $1 billion, a figure widely understood to represent a fraction of the total capital invested in acquisitions, development, and deployment across the life of the program.
The core failure wasn’t the technology itself. As researchers and analysts have since noted, the problem was structural and organizational. IBM’s leadership scaled the product before the conditions for it to work were established. There was no rigorous governance to catch the gap between what was being promised externally and what was actually possible internally. Clinical experts weren’t embedded deeply enough. The business case was built on narrative rather than evidence.
This is precisely what happens when AI adoption is treated as a product launch rather than as an organization-wide capability change that requires sustained leadership ownership at every level.
Source: Henrico Dolfing Case Study Analysis, December 2024
What Leaders Actually Need to Do Differently
The answer to “leadership isn’t driving AI adoption” isn’t to send another memo or mandate a new tool. It is to change behavior, specifically leadership behavior, in visible and consistent ways.
Here’s what that looks like in practice.
Use the tools publicly. When a CEO shares that they used AI to prepare for a board meeting, or a VP mentions in a team call that they ran a prompt to summarize competitive research, those small moments signal that AI is real, not aspirational. Visibility matters enormously.
Ask AI-related questions in reviews. If the only metrics being reviewed are the same ones from two years ago, nothing changes. Leaders who ask “how did we use AI to get this result?” or “where did AI save us time this quarter?” are reshaping what the team pays attention to.
Assign explicit ownership. Not a committee. Not a shared responsibility. One named person whose job includes making AI adoption work, with a budget, a timeline, and reporting lines directly into leadership. As our analysis of why leadership must drive AI agent adoption shows, the moment there is no single owner, accountability evaporates.
Remove the barriers teams face. Most frontline employees aren’t anti-AI. They’re time-poor, risk-averse, and waiting for permission. Leaders need to create psychological safety around experimentation, reduce the bureaucratic friction around tool access, and make it easy to try things without fear of looking incompetent.
Tie AI outcomes to performance conversations. What gets measured gets done. When teams know that AI capability building is part of how they are evaluated, they prioritize it.
The Readiness Problem Leaders Keep Ignoring
Leadership behavior is only one part of the equation. Even the most committed executive can’t drive adoption if the organization’s infrastructure isn’t ready for AI agents to work.
This is a critical point that gets skipped in most leadership conversations about AI.
Your AI agents are only as reliable as the data and systems they operate in. If knowledge is scattered across tools and teams, agents won’t find what they need. We cover this challenge in depth in our piece on why scattered knowledge is silently sabotaging your AI, and in our blog on scattered knowledge and AI agent readiness.
If your documented processes don’t reflect how work actually happens, agents will make decisions based on outdated or wrong information. This is explored in our piece on what happens when your documentation lies, and in our undocumented workflows blog.
If different teams are working from different versions of the same data, the conflict kills AI decision quality before it even starts. Our article on multiple versions of truth and why conflicting data kills your AI makes this concrete, and our blog on multiple versions of truth walks through the fix.
If agents can’t access real-time data, every decision they make is already stale. We break this down in why real-time data access is the hidden reason your AI agents stall and in our blog on AI agents failing without real-time data access.
And if there are no approval or review layers, no metrics for performance, and security systems that were designed for humans rather than autonomous agents, you’re not just slowing adoption down. You’re creating risk. These exact gaps are covered in our deep dives on AI agents with no approval or review layer, security built only for humans, and no metrics for AI performance.
Leaders who genuinely want to drive AI adoption have to ask: are we actually ready for agents to operate here? Or are we trying to drive on a road that hasn’t been built yet?
The Leadership Gap vs. The Readiness Gap: A Practical Framework
Understanding both gaps helps you prioritize the right interventions. Here is a simple way to think about where your organization stands.
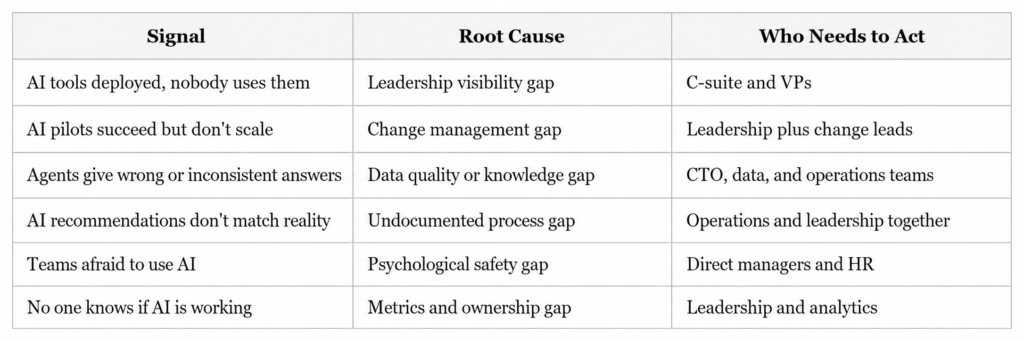
Most organizations have problems in multiple columns at once. The common thread is that none of these get fixed without leadership actively identifying the problem, naming it publicly, and committing resources to solve it.
Three Questions Every Leadership Team Should Answer This Quarter
If you’re serious about closing the gap between “we have AI” and “AI is working for us,” start with these three questions in your next leadership session.
One: Where is AI visibly showing up in our leadership behavior? Not in slides. In actual day-to-day decisions, communications, and reviews. If the honest answer is “not really anywhere,” that’s where to start.
Two: Who owns AI outcomes across this organization? Not IT. Not a vendor. A named individual with authority, accountability, and a direct line to leadership. If you can’t answer this in thirty seconds, ownership doesn’t exist.
Three: What does success look like in ninety days? Not annual ROI projections. A concrete, measurable outcome that proves the investment is moving in the right direction. If there’s no near-term success metric, there’s no accountability loop.
These aren’t complicated questions. But they require an honest conversation that many leadership teams keep avoiding because they’re busy and because the status quo feels comfortable.
The status quo, meanwhile, is getting more expensive every quarter.
What High-Performing Organizations Do Differently
McKinsey’s research identifies a consistent pattern among AI high performers. They’re not necessarily the companies with the biggest budgets or the most sophisticated technology. They’re the companies where senior leaders demonstrate visible ownership of AI initiatives, actively use AI themselves, and role-model the adoption behavior they want to see.
These organizations treat AI not as an IT capability but as a business capability. The difference in framing changes everything: who owns it, how it’s resourced, how progress is measured, and how it’s talked about internally.
They also do something that most organizations skip. They redesign workflows rather than bolting AI onto existing ones. Leaders at these companies are willing to ask harder questions about how work actually flows, where decisions get made, and what needs to change structurally for AI to deliver real value.
That kind of organizational introspection doesn’t happen at the team level. It requires leadership to drive it.
Conclusion: Adoption Starts at the Top, Not at the Tool
There’s a version of this story that ends well, and a version that doesn’t. The difference isn’t the quality of the AI tools, the size of the implementation budget, or the enthusiasm of the early adopters.
The difference is whether your leaders treat AI as someone else’s problem or as their own.
When leadership isn’t driving AI adoption, you get pilots without scale, investments without returns, and teams that quietly go back to doing things the way they always have. When leadership does drive it, you get the 3x performance multiplier McKinsey observed. You get teams that feel permission and urgency to change. You get an organization that actually transforms.
The infographic above puts it plainly: “If leaders don’t actively use AI, teams won’t prioritize it. Adoption starts at the top.” That’s not a motivational phrase. That is an operational truth backed by the data.
Your next move is not another pilot. It’s a leadership conversation about ownership, visibility, and accountability. Start there, and everything else becomes easier.
Ready to Assess Your AI Agent Readiness?
At Ysquare Technology, we help enterprise and growth-stage companies identify exactly where their AI adoption is breaking down and what leadership, data, and infrastructure changes are needed to fix it.
If your AI investments aren’t delivering what you expected, the problem is almost certainly upstream of the technology. Let’s find it together.
Connect with us on LinkedIn or visit www.ysquaretechnology.com to start the conversation.
Read More
Ysquare Technology
01/06/2026







