
Why AI Agents Fail Without Real-Time Data: The Infrastructure Gap

You’ve deployed AI agents. The demos looked impressive. The pilot went smoothly. Then you pushed to production and everything started breaking in ways you didn’t expect.
Sound familiar?
Here’s what most organizations discover too late: the difference between AI agents that work and AI agents that fail catastrophically isn’t about the model, the training data, or even the architecture. It’s about something far more fundamental—whether your agents can access current information when they need to make decisions.
Real-time data access for AI agents isn’t a luxury feature you add later. It’s the foundational infrastructure that determines whether autonomous systems can function reliably at all.
Most companies building AI agents today are essentially constructing sophisticated decision-making engines and then feeding them information that’s already outdated. They’re surprised when those agents make terrible decisions—but the failure was built in from the start.
Let’s talk about why this happens, what real-time data access actually means in practice, and what you need to build if you want AI agents that don’t just work in demos but actually deliver value in production.
Understanding Real-Time Data Access: What It Actually Means
Real-time data access means your AI agents can query and retrieve current information with minimal latency—typically milliseconds to seconds—rather than working from periodic batch updates that might be hours or days old.
This isn’t about making batch processing faster. It’s a fundamentally different approach to how data moves through your systems.
Traditional batch processing says: collect data throughout the day, process it in chunks during off-peak hours, and make updated datasets available periodically. Your morning report contains yesterday’s data. Your agent making a decision at 2 PM is working with information from last night’s batch job.
Streaming architectures say: treat every data change as an immediate event, process it the moment it occurs, and make it queryable within milliseconds. Your agent making a decision at 2 PM sees what’s happening at 2 PM.
For AI agents making autonomous decisions, that difference isn’t just about speed. It’s about whether the decision is based on reality or on a snapshot that no longer reflects the current state of your business.
According to research from CIO Magazine, modern fraud detection systems now correlate transactions with real-time device fingerprints and geolocation patterns to block fraud in milliseconds. The system can’t wait for the nightly batch update. By then, the fraudulent transaction has already settled and the money is gone.
The Hidden Cost of Stale Data in AI Agent Deployments

Here’s what makes stale data particularly dangerous for AI agents: the failure mode is silent.
When a traditional application encounters bad data, it often throws an error or crashes in obvious ways. You know something’s wrong because the system stops working.
AI agents don’t fail like that. They keep running. They keep making decisions. Those decisions just get progressively worse as the gap between their information and reality widens.
Research from Shelf found that outdated information leads to temporal drift, where AI agents generate responses based on obsolete knowledge. This is particularly critical for Retrieval-Augmented Generation (RAG) systems, where stale data produces incorrect recommendations that look authoritative because they’re well-formatted and delivered with confidence.
Think about what this means in a real business context:
Your customer service agent promises a shipping timeline based on inventory data from this morning. But there was a warehouse issue three hours ago that your logistics team resolved by redirecting shipments. The agent doesn’t know. It commits to dates you can’t meet. When documentation doesn’t reflect actual processes, agents make promises the business can’t keep.
Your pricing agent calculates a quote using rate tables that were updated yesterday, but your largest supplier announced a price increase this morning. Your quote is now below cost. You won’t know until the order processes and someone manually reviews the margin.
Your fraud detection system flags a legitimate high-value transaction from your best customer. Why? Because it’s comparing against behavior patterns that are six hours old. In those six hours, the customer landed in a different country for a business trip. The agent sees the transaction location, doesn’t see the updated travel status, and blocks the purchase.
None of these scenarios involve model failure. The AI is working exactly as designed. The infrastructure is the problem.
Why 88% of AI Agents Never Make It to Production
According to comprehensive analysis of agentic AI statistics, 88% of AI agents fail to reach production deployment. The 12% that succeed deliver an average ROI of 171% (192% in the US market).
What separates the winners from the failures?
Most organizations assume it’s about the sophistication of the model or the quality of the training data. Those factors matter, but they’re not the primary differentiator.
The real gap is infrastructure.
Deloitte’s 2025 Emerging Technology Trends study found that while 30% of organizations are exploring agentic AI and 38% are piloting solutions, only 14% have systems ready for deployment. The primary bottleneck cited? Data architecture.
Nearly half of organizations (48%) report that data searchability and reusability are their top barriers to AI automation. That’s code for: “our data infrastructure can’t support what these agents need to do.”
Organizations with scattered knowledge across multiple systems face compounded challenges—when agents can’t find authoritative, current information, they either make decisions with incomplete data or become paralyzed by conflicting sources.
Here’s the pattern that plays out repeatedly:
Pilot phase: Controlled environment, limited data sources, manageable complexity. The agent works because you’ve carefully curated its information access.
Production deployment: Real-world complexity, dozens of data sources, conflicting information, latency issues, and stale data scattered across systems. The agent that worked perfectly in the pilot now makes unreliable decisions because the infrastructure can’t deliver current, consistent information at scale.
The companies that close this gap are the ones investing in boring infrastructure: Change Data Capture (CDC) pipelines, streaming platforms, semantic layers, and data freshness monitoring. Not sexy. Absolutely critical.
The Real-Time Data Infrastructure Stack for AI Agents
If you’re serious about deploying AI agents that work in production, here’s what the infrastructure stack actually looks like:
Source Systems with CDC Pipelines
Your databases, CRMs, ERPs, and operational systems need Change Data Capture enabled. Every insert, update, and delete gets captured as an event the moment it happens. Tools like Debezium, Streamkap, or AWS DMS handle this layer.
Streaming Platform
Those events flow into a streaming platform—Apache Kafka, Apache Pulsar, AWS Kinesis, or Google Cloud Pub/Sub. This is your real-time data backbone. Events are processed immediately and made available to consumers within milliseconds.
According to the 2026 Data Streaming Landscape analysis, 90% of IT leaders are increasing their investments in data streaming infrastructure specifically to support AI agents. Market research suggests 80% of AI applications will use streaming data by 2026.
Semantic Layer
Raw data isn’t enough. AI agents need context. A semantic layer sits on top of your streaming data to provide business definitions, relationship mappings, and data quality rules. This layer answers questions like “what does ‘active customer’ actually mean?” and “which revenue figure is the source of truth?”
Data Freshness Monitoring
You need systems that continuously track when data was last updated and alert you when freshness degrades. This isn’t traditional uptime monitoring—it’s monitoring whether the data your agents are accessing is still current enough to support reliable decisions.
Agent Query Layer
Finally, your AI agents need an optimized query interface that lets them access both current state and historical context with minimal latency. This might be a high-performance database like Aerospike, a data lakehouse like Databricks, or a specialized vector database for RAG applications.
Research from Aerospike emphasizes that organizations must invest in a data backbone delivering both ultra-low latency and massive scalability. AI agents thrive on fast, fresh data streams—the need for accurate, comprehensive, real-time data that scales cannot be overstated.
What Happens When You Skip the Infrastructure Investment
Let’s be direct: you can’t retrofit real-time data access onto batch-based architectures and expect it to work reliably.
The companies trying this approach encounter predictable failure patterns:
Race Conditions: Agent A makes a decision based on data snapshot 1. Agent B makes a conflicting decision based on snapshot 2. Neither knows about the other’s action because the data layer doesn’t synchronize in real time.
Context Staleness: According to analysis of AI context failures, agents frequently have access to both current and outdated information but default to the stale version because it ranked higher in similarity search or was cached more aggressively.
Orchestration Drift: Research from InfoWorld found that agent-related production incidents dropped 71% after deploying event-based coordination infrastructure. Most eliminated incidents were race conditions and stale context bugs that are structurally impossible with proper real-time architecture.
Silent Degradation: The system doesn’t fail obviously. It just makes worse decisions over time as data freshness degrades. By the time you notice the problem, you’ve already made hundreds or thousands of bad decisions.
Here’s a real example from production failure analysis: a sales agent connected to Confluence and Salesforce worked perfectly in demos. In production, it offered a major customer a 50% discount nobody authorized. The root cause? An outdated pricing document in Confluence still referenced a promotional rate from two quarters ago. The agent treated it as current because nothing in the infrastructure flagged it as stale.
The documentation-reality gap isn’t just an accuracy problem—it’s a trust-destruction mechanism that makes AI agents unreliable at scale.
The Economics of Real-Time: When Does It Actually Pay Off?
Real-time data infrastructure isn’t cheap. Streaming platforms, CDC pipelines, semantic layers, and monitoring systems require investment in technology, engineering time, and operational overhead.
So when does it actually make economic sense?
Cloud-native data pipeline deployments are delivering 3.7× ROI on average according to Alation’s 2026 analysis, with the clearest gains in fraud detection, predictive maintenance, and real-time customer personalization.
The ROI calculation comes down to three factors:
Decision Velocity: How quickly do conditions change in your business? If you’re in e-commerce, financial services, logistics, or healthcare, conditions change by the minute. Batch processing means your agents are always operating with outdated information. The cost of wrong decisions based on stale data exceeds the infrastructure investment.
Decision Consequence: What’s the cost of a single wrong decision? In fraud detection, one missed fraudulent transaction can cost thousands of dollars. In healthcare, one outdated patient data point can have life-threatening consequences. High-consequence decisions justify real-time infrastructure.
Scale of Automation: How many autonomous decisions are your agents making per day? If it’s dozens, batch processing might be adequate. If it’s thousands or millions, the aggregate cost of decision errors from stale data quickly outweighs infrastructure costs.
According to comprehensive statistics on agentic AI adoption, the global AI agents market is projected to grow from $7.63 billion in 2025 to $182.97 billion by 2033—a 49.6% compound annual growth rate. That explosive growth is happening because organizations are discovering that agents with proper data infrastructure actually deliver value.
Building Real-Time Capability: A Practical Roadmap
If you’re starting from batch-based infrastructure and need to support AI agents with real-time data access, here’s a practical migration path:
Phase 1: Identify Critical Data Sources
Not all data needs real-time access. Start by identifying which data sources your AI agents actually query for autonomous decisions. Customer data? Inventory? Pricing? Transaction history? Map the data flows and prioritize based on decision frequency and consequence.
Phase 2: Implement CDC on High-Priority Sources
Enable Change Data Capture on your most critical databases. This captures every change as it happens and streams it to your data platform. Start with one or two sources, validate that the pipeline works reliably, then expand.
Phase 3: Deploy Streaming Infrastructure
Stand up your streaming platform—whether that’s Kafka, Pulsar, Kinesis, or another solution depends on your cloud strategy and technical requirements. Configure it for high availability and monitoring from day one.
Phase 4: Build the Semantic Layer
This is where many organizations stumble. Raw event streams aren’t enough—you need business context. Invest in data catalog tools, governance frameworks, and automated metadata management. Organizations struggling with scattered knowledge across systems need this layer to provide agents with authoritative, consistent definitions.
Phase 5: Implement Freshness Monitoring
Deploy monitoring systems that track data age and alert when freshness degrades below acceptable thresholds. This is your early warning system for infrastructure problems that would otherwise manifest as agent decision errors.
Phase 6: Migrate Agent Queries
Gradually migrate your AI agents from batch data queries to real-time streams. Do this incrementally, validating that decision quality improves before moving to the next agent or use case.
The timeline for this migration typically ranges from 3-9 months depending on your starting point and organizational complexity. The companies succeeding with AI agents built this infrastructure before deploying agents widely—not after pilots failed in production.
The Questions Your Leadership Team Should Be Asking
If you’re presenting AI agent initiatives to executives or board members, here are the infrastructure questions they should be asking (and you should be prepared to answer):
How fresh is the data our agents are accessing? If the answer is “it varies” or “I’m not sure,” that’s a red flag. Data freshness should be measurable, monitored, and consistent.
What happens when data sources conflict? Multiple systems often contain different versions of the same information. Which source is authoritative? How do agents know which to trust? If you don’t have clear answers, agents will make arbitrary choices.
Can we trace agent decisions back to the data that informed them? For regulatory compliance, debugging, and trust-building, you need data lineage. Every agent decision should be traceable to specific data sources with timestamps.
What’s our plan for scaling this infrastructure? Real-time data platforms need to handle increasing volumes as you deploy more agents and integrate more data sources. What’s your scaling strategy?
How do we know when data goes stale? Monitoring uptime isn’t enough. You need monitoring that tracks data age and alerts when freshness degrades before it impacts decision quality.
According to analysis from MIT Technology Review, in late 2025 nearly two-thirds of companies were experimenting with AI agents, while 88% were using AI in at least one business function. Yet only one in 10 companies actually scaled their agents. The infrastructure gap is the primary reason.
Real-Time Data Access: The Competitive Moat You’re Building
Here’s the strategic insight most organizations miss: real-time data infrastructure for AI agents isn’t just an operational necessity. It’s a competitive moat.
The companies investing in this infrastructure now are building capabilities their competitors can’t easily replicate. Streaming data platforms, semantic layers, and data freshness monitoring create compound advantages:
Faster Time to Value: Once the infrastructure exists, deploying new AI agents becomes dramatically faster because the hard part—reliable data access—is already solved.
Higher Quality Decisions: Agents making decisions on current data consistently outperform agents working with stale information. That quality difference compounds over thousands of decisions daily.
Organizational Learning: Real-time infrastructure enables feedback loops that make agents smarter over time. Batch-based systems can’t close these loops fast enough to drive continuous improvement.
Regulatory Confidence: In industries with strict compliance requirements, being able to demonstrate that agent decisions are based on current, traceable data creates regulatory confidence that competitors lacking this capability can’t match.
Research indicates that AI-driven traffic grew 187% from January to December 2025, while traffic from AI agents and agentic browsers grew 7,851% year over year. The organizations capturing value from this explosion are the ones with infrastructure that supports reliable, real-time autonomous operations.
The Bottom Line on Real-Time Data for AI Agents
Real-time data access isn’t a feature. It’s the foundation.
If you’re deploying AI agents on batch-processed data, you’re deploying agents that will make outdated decisions. Some percentage of those decisions will be wrong. The only questions are: what percentage, and what will those mistakes cost?
The uncomfortable truth is that most AI agent failures aren’t model problems—they’re infrastructure problems. Organizations keep chasing better models while ignoring the data architecture that determines whether those models can function reliably.
According to comprehensive research on AI agent production failures, 27% of failures trace directly to data quality and freshness issues—not model design or harness architecture. The agents that succeed are the ones with infrastructure that delivers current, consistent, contextualized data at the moment of decision.
The companies winning with AI agents in 2026 are the ones that invested in streaming platforms, CDC pipelines, semantic layers, and freshness monitoring before deploying agents broadly. The companies still struggling are the ones trying to retrofit real-time capabilities onto batch architectures after pilots failed.
Which category does your organization fall into?
If you’re not sure, read our detailed analysis on real-time data access for AI agents for a deeper dive into the infrastructure decisions that determine whether AI agents work or fail at scale.
The window for building this as a competitive advantage is closing. Soon it will just be table stakes. The question is whether you’re building it now or explaining to your board later why your AI agents couldn’t deliver the promised value.
Frequently Asked Questions
1. What exactly is real-time data access for AI agents?
Real-time data access means AI agents can query and retrieve current information with minimal latency—typically milliseconds to seconds instead of relying on periodic batch updates that might be hours or days old. This enables agents to make decisions based on the actual current state of systems, customers, inventory, or transactions rather than historical snapshots that no longer reflect reality.
2. Why can't AI agents work effectively with batch-processed data?
AI agents treat the data they receive as ground truth and make autonomous decisions based on that information. Unlike humans who can interpolate and apply judgment to outdated data, agents can't reliably determine when information is stale or adjust their decisions accordingly. When batch-processed data introduces hours or days of latency, agents systematically make decisions based on conditions that have already changed, leading to errors that compound at scale.
3. What are the most common failure modes when AI agents use stale data?
Common failure modes include temporal drift (agents acting on obsolete knowledge), context staleness (defaulting to older cached data when fresher data exists), race conditions (multiple agents making conflicting decisions due to unsynchronized data), and silent degradation (decision quality eroding gradually without obvious system failures). Research shows these failures often go undetected for weeks because agents don't crash—they just make progressively worse decisions.
4. How much does real-time data infrastructure actually cost?
Infrastructure costs vary widely based on data volume, number of sources, and architecture complexity, but organizations report 3.7× average ROI from cloud-native data pipeline deployments. The investment includes streaming platforms (Kafka, Pulsar, Kinesis), CDC pipeline tools, semantic layer development, and monitoring systems. However, the cost of not having this infrastructure—in failed deployments, wrong decisions, and lost competitive advantage—typically far exceeds the infrastructure investment for high-velocity, high-consequence decision environments.
5. Can we add real-time data access to our existing AI agents, or do we need to rebuild?
Retrofitting real-time capabilities onto batch-based architectures rarely works reliably. The companies succeeding with AI agents built streaming data infrastructure first and deployed agents second. Attempting to bolt real-time access onto existing batch pipelines typically creates race conditions, inconsistent state, and reliability problems. A phased migration approach—implementing CDC on critical sources, deploying streaming infrastructure, building semantic layers, then gradually migrating agent queries—is more practical than trying to run both architectures simultaneously.
6. What's the difference between streaming data and just running batch jobs more frequently?
Streaming data treats each change as an immediate event that's processed and made queryable in milliseconds. Batch processing, even at high frequency (every 15 minutes, for example), still introduces systematic latency between when something happens and when agents can see it. For fraud detection, supply chain optimization, or customer service scenarios, that latency window is where problems occur. Streaming architecture also enables event-driven decision-making—agents can react to changes as they happen rather than polling for updates.
7. How do we measure whether our data is fresh enough for AI agents?
Implement data freshness monitoring that tracks when each data source was last updated and alerts when age exceeds defined thresholds. For critical decision data, freshness should be measured in seconds or minutes, not hours. Track metrics like: time since last update, percentage of queries served from stale data, decision errors attributable to data latency, and average data age at decision time. These metrics should be continuously monitored and alerting on degradation before it impacts agent reliability.
8. Which AI agent use cases absolutely require real-time data access?
Any use case where conditions change frequently and decisions have meaningful consequences requires real-time data: fraud detection (transaction patterns change by the second), customer service (account status, order tracking, inventory availability), supply chain optimization (demand signals, inventory levels, logistics disruptions), pricing engines (market conditions, competitor pricing, cost fluctuations), and healthcare (patient monitoring, treatment recommendations, clinical alerts). If decisions become wrong or obsolete within minutes to hours, real-time infrastructure is non-negotiable.
9. How does real-time data access affect AI agent accuracy and reliability?
Research shows that 27% of AI agent production failures trace to data quality and freshness issues. Agents with real-time data access make decisions based on current conditions rather than historical assumptions, dramatically reducing errors from temporal drift. Organizations report 71% reductions in production incidents after deploying event-based coordination infrastructure. The impact isn't just fewer errors—it's faster feedback loops that enable continuous improvement as agents learn from outcomes in near-real-time.
10. What are the first steps for organizations wanting to implement real-time data for AI agents?
Start with a data access audit: identify which sources your AI agents query for autonomous decisions, map current data freshness for each source, and quantify the cost of decision errors from stale data. Prioritize high-frequency, high-consequence decision data for real-time migration. Implement CDC on 1-2 critical sources as a proof of concept, deploy streaming infrastructure with monitoring from day one, and validate improved decision quality before expanding. Most importantly, build the semantic layer alongside streaming infrastructure—raw real-time data without business context doesn't solve the problem.

No Defined Boundaries for AI Agents: Why Enterprise AI Deployments Fail
Your AI agent just sent 4,000 emails to the wrong list. It updated every record in your CRM with incorrect pricing. It deleted a folder your legal team needed for an audit.
None of that happened because the AI malfunctioned.
It happened because nobody told the AI what it was not allowed to do.
This is sign number 13 of the 15 signs your organization is not ready for AI agents: no defined boundaries. And if you are a CEO, CTO, or senior leader evaluating AI deployment right now, this one deserves more attention than almost anything else on that list.
Unrestricted AI agents are not just a technical risk. They are a governance risk, a compliance risk, and a business continuity risk.
When an autonomous system can act without limits, every mistake it makes scales instantly across your entire operation.
Here is the thing most vendors will not tell you: the most dangerous thing about a powerful AI agent is not that it will fail to perform. It is that it will perform extremely well, in completely the wrong direction.
What “No Defined Boundaries” Actually Means in an AI Agent Context
When we say an AI agent has no defined boundaries, we are not talking about the agent going rogue in some science fiction sense.
We are talking about something far more common and far more damaging: an agent that has been given a goal without being given the guardrails that define how far it can go to achieve that goal.
Think of it this way. You hire a new employee and tell them to “improve customer response times.” Without further instruction, they might reasonably decide to disable the approval layer on all outbound communications, auto-close support tickets after 10 minutes, and send bulk updates to every customer who has an open case.
Technically, response times improved.
Practically, your customer trust just collapsed.
AI agents operate on the same logic. They optimize for the objective they have been given. If you have not told the agent what it cannot do, it will find the most efficient path to its goal, and that path may cross every boundary your business depends on.
AI agent scope limits are not a feature you add later. They are a foundational requirement.
Without them, you do not have an AI agent. You have a liability engine running at machine speed.
Here is what undefined boundaries look like in practice:
- An agent with access to your email system sends automated responses to clients without a review step.
- An agent managing inventory places purchase orders beyond budget thresholds because no spending cap was defined.
- An agent analyzing HR data accesses employee records outside its designated scope because nobody restricted which data sets it could query.
These scenarios are not far from reality. They are the predictable outcome of deploying AI agents without establishing what they are and are not allowed to do.
Why Leaders Underestimate This Risk Until It Is Too Late
Here is the pattern we see repeatedly with enterprise AI deployments: leadership approves the use case, the technical team deploys the agent, and the boundary question gets deferred to a later phase.
That later phase often never comes.
Part of the reason is how AI agents are sold and marketed. The emphasis is always on capability: what the agent can do, how fast it can act, how much it can automate.
The conversation about what the agent should never do gets far less attention.
The other reason is that the risk is invisible until it becomes a crisis. An agent operating without defined limits will often perform well in early testing, precisely because early testing environments are controlled.
The moment you scale to production, with real data, real customers, and real stakes, the absence of boundaries becomes catastrophic.
We have covered the downstream effects of poor governance in our earlier posts on no clear AI ownership in organizations and no metrics for AI performance. Undefined boundaries are what make both of those problems impossible to fix after the fact.
Leadership teams tend to think of AI risk in terms of the AI failing to deliver results.
The more sophisticated and more urgent risk is the AI delivering results that were never authorized.
AI agent governance cannot be an afterthought. It has to be the first conversation, not the last.
The Five Boundaries Every Enterprise AI Agent Needs Before Deployment
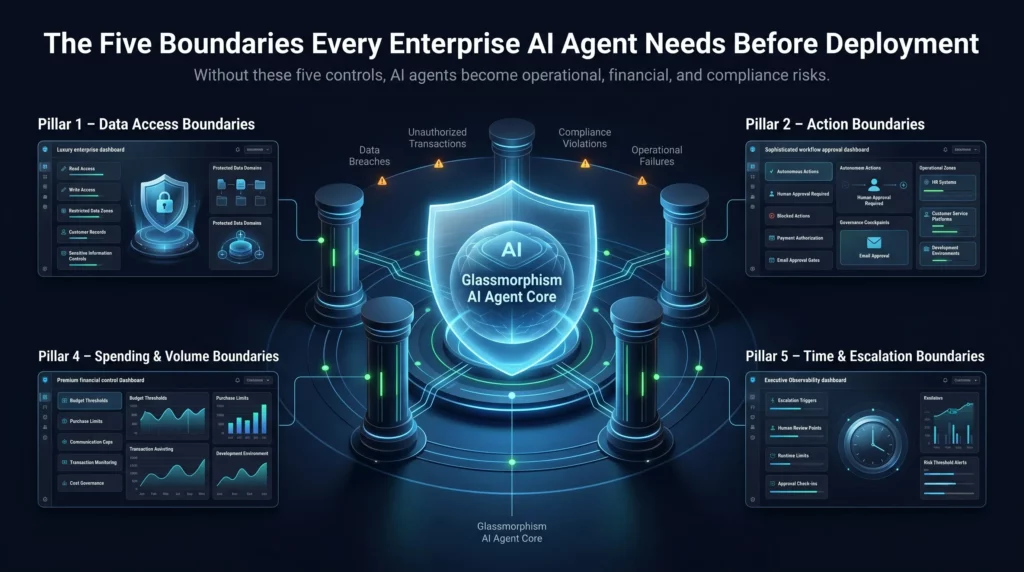
If your organization is deploying or evaluating AI agents, these are the five boundary categories your governance framework must address before a single agent goes live.
1. Data Access Boundaries
The first question to answer is: what data can the agent read, what can it write, and what is completely off limits?
An agent with read access to customer records should not have write access unless that specific action is part of its authorized function.
Data access boundaries prevent agents from inadvertently exposing, corrupting, or leaking sensitive information.
We have written in detail about how poor data quality undermines AI agent performance, but even clean data becomes a liability when accessed by an agent without scope restrictions.
2. Action Boundaries
Not every action an agent can perform should be performed autonomously.
Some tasks need human approval before execution. An agent that can send emails, initiate payments, update records, and trigger workflows needs clear action tiers.
Some actions can be fully autonomous. Others must trigger a review, and some should be permanently blocked.
This connects directly to the approval and review layer your AI deployment needs. Without action boundaries, there is nothing for that review layer to enforce.
3. Scope Boundaries
Scope boundaries answer a simple but critical question: where does this agent belong, and where does it not?
An HR agent should not have the ability to reach into financial systems. Likewise, a customer service agent should not have access to internal development environments.
Scope boundaries define the operational territory the agent is allowed to occupy.
4. Spending and Volume Boundaries
If the agent can trigger transactions, orders, or communications at scale, what are the caps?
A purchasing agent without spending limits can drain a budget in hours. A marketing agent without volume caps can trigger spam filters, damage email deliverability, or violate communications regulations.
5. Time and Escalation Boundaries
When should the agent stop and wait for a human?
How long should it operate autonomously before requiring a check-in? What triggers escalation?
Time boundaries prevent agents from compounding errors over extended periods before anyone notices something has gone wrong.
Unrestricted AI Actions and the Compliance Exposure Most Leaders Miss
There is a regulatory dimension to undefined AI agent boundaries that deserves direct attention, especially for organizations in healthcare, financial services, and any sector handling personal data.
When an AI agent takes an action that violates a data handling requirement, the organization is still responsible.
This includes actions such as accessing records it should not access, sending communications that breach consent rules, or retaining data beyond permitted periods.
Regulators are unlikely to accept “the AI acted on its own” as a sufficient explanation. Autonomous systems that operate under your organizational umbrella are still part of your operational responsibility.
If those systems did not have defined boundaries, that gap in governance can create serious audit, legal, and reputational exposure.
Security built only for humans is a related problem we have covered in depth. Traditional access controls assume a human is making decisions.
AI agents act at a speed and scale that completely outpaces human-designed security models. Boundary definitions are how you extend governance to autonomous behavior.
In sectors like healthcare and pharma, where we work extensively at Ysquare Technology, this compliance exposure is not theoretical. It is the difference between a successful deployment and a regulatory investigation.
How Undefined Boundaries Connect to the Other 14 Readiness Gaps
No defined boundaries does not exist in isolation. It is the consequence and the amplifier of several other readiness gaps your organization may already be experiencing.
If your knowledge is scattered across multiple tools and teams, as we covered in our post on scattered knowledge silently sabotaging AI agents, an agent without boundaries will query all of it, including the parts it should never touch.
The same challenge applies to documentation that does not match reality: if the agent is navigating processes that exist only in people’s heads, it has no map and no limits.
When there are multiple versions of truth in your data environment, an agent without scope restrictions will pull from all of them and produce outputs that are confidently wrong.
When real-time data access is missing, an agent trying to make decisions without boundaries compounds outdated information into operational errors.
Leadership not driving AI adoption is also directly connected here.
Boundary setting is a leadership decision, not a technical one. It requires executives to define what the organization is and is not willing to authorize AI to do.
When leaders are not actively involved in AI governance, boundary definitions get left to whoever deployed the agent, and they rarely have the authority or context to make those calls correctly.
The Pulse articles we have published on real-time data access, documentation failures, and scattered knowledge each point to the same underlying gap: organizations are deploying AI capability without deploying the governance that makes that capability safe.
Undefined boundaries are what happens when you stack all of those gaps together and hand the result a set of automation tools.
What Responsible AI Agent Deployment Actually Looks Like
The good news is that defining AI agent boundaries is not technically complex.
The challenge is organizational.
It requires the right people to be in the room, asking the right questions, before deployment begins.
Here is the practical framework we recommend:
1. Start with an authorization matrix.
For every function the agent will perform, define whether it is fully autonomous, requires notification, or requires approval. Build this matrix with input from legal, compliance, operations, and the technical team, not just the team deploying the agent.
2. Define exclusions explicitly.
Most governance frameworks focus on what the agent should do. Equally important is a written list of what it must never do. These exclusions should be documented, version-controlled, and reviewed regularly.
3. Build in hard limits at the system level.
Do not rely on prompt instructions alone to enforce boundaries. Hard technical limits, including spending caps, volume restrictions, and data access controls, should be enforced at the infrastructure level, not the instruction level.
4. Test for boundary violations before launch.
Before any agent goes live, run scenarios specifically designed to push the agent toward its limits. See what it does when it reaches a boundary. See what it does when someone tries to instruct it to cross one.
5. Assign ownership of the boundary framework.
Someone specific, a role not a committee, needs to be accountable for maintaining and updating the boundary definitions as the agent’s scope evolves. This connects directly to the no clear AI ownership problem we have documented across enterprise deployments.
The Real Question Every CEO and CTO Should Be Asking
Here is the real question most enterprise AI evaluations skip entirely:
“What is the worst thing our AI agent could do if it performed exactly as designed but in the wrong context?”
If you cannot answer that question, you are not ready to deploy.
The ability to define boundaries is not a sign of distrust in AI technology. It is the mark of organizational maturity.
The companies that get the most from AI agents are not the ones that gave those agents the most freedom. They are the ones that built the clearest operational contracts, defining what the agent is responsible for and what it is explicitly not.
AI agents are not magic. They are powerful tools operating within an organizational system.
Every powerful tool needs defined operating parameters.
A scalpel is extraordinary in a surgeon’s hand and dangerous without one. An AI agent without boundaries is no different.
The organizations we see deploying AI successfully, in healthcare systems, enterprise software, and large-scale operations, all share one thing: they treated boundary definition as a first-order requirement, not an afterthought.
They answered the hard governance questions before they wrote a single line of deployment code.
That is the bar your AI agent readiness framework needs to clear.
Conclusion
No defined boundaries for AI agents is not a technical problem with a technical solution.
It is a governance problem that requires organizational leadership to solve.
If you are assessing your organization’s readiness to deploy AI agents, boundary definition should be one of the first items on your evaluation checklist.
Not because you distrust the technology, but because the technology will do exactly what it is capable of doing. Without limits, that capability can eventually create consequences your business cannot absorb.
The 15 signs of AI agent unreadiness are not independent problems. They reinforce each other.
But no defined boundaries is the one that turns all the others into active risks.
Fix this one, and you make every other gap manageable. Leave it unaddressed, and every other AI investment you make becomes harder to protect.
At Ysquare Technology, we work with healthcare organizations, enterprise technology companies, and operations-driven businesses to build AI agent governance frameworks that are practical, auditable, and built to scale.
If your organization is preparing to deploy AI agents, Ysquare Technology can help you define practical governance boundaries, approval workflows, secure access controls, and scalable operating models before deployment.
Read More

Ysquare Technology
15/06/2026

Poor Data Quality Is Silently Killing Your AI Agent Strategy
Your AI agents are not the problem. Your data is.
Most organizations investing heavily in AI automation hit the same invisible wall. The tools are purchased, the agents are deployed, and the dashboards look impressive. But the outputs are wrong. Decisions are off. The team loses trust in the system within weeks.
Here is the real reason: poor data quality is quietly undermining everything your AI agents are supposed to do. It is not a technology failure. It is a data failure that was always there, just waiting for an autonomous system to expose it at scale.
This is the twelfth sign in the AI Agent Readiness Series, which examines fifteen critical gaps that prevent organizations from running AI agents reliably. If your AI agents are producing unreliable outputs, inconsistent results, or decisions that nobody trusts, data quality is almost certainly the root cause. Let us get into exactly why, and what you can do about it.
What Poor Data Quality Actually Means for AI Agents
Most executives interpret data quality as a technical concern they delegate to their data teams. That is understandable, but it misses the real business exposure.
For AI agents, data quality is not just about clean spreadsheets or well-labelled databases. It covers every piece of information an agent reads, references, or acts on when executing a task. That means CRM records with inconsistent customer names, ERP entries with missing cost codes, product catalogues with outdated pricing, and patient records with duplicate entries across systems.
AI agents do not verify data before they use it. They cannot pause and say this looks wrong. They process what they are given and produce outputs accordingly. When the input is corrupted, incomplete, or contradictory, the agent delivers garbage outputs at the speed of automation.
The old principle applies perfectly here: garbage in equals garbage out. The difference is that a human analyst might catch an anomaly before it becomes a decision. An AI agent running at scale will not.
Here is what that looks like in practice. An agent managing procurement approvals reads outdated supplier pricing data and commits to orders at rates that are no longer valid. An agent handling patient scheduling pulls from a record that has not been updated since a system migration, and books appointments for inactive patients. An agent producing financial summaries aggregates figures from two databases that use different fiscal calendar definitions.
None of these failures are caused by the AI being wrong. They are caused by the data being wrong. Understanding this distinction is the first step toward fixing it.
The Three Most Dangerous Forms of Poor Data Quality in AI Deployments
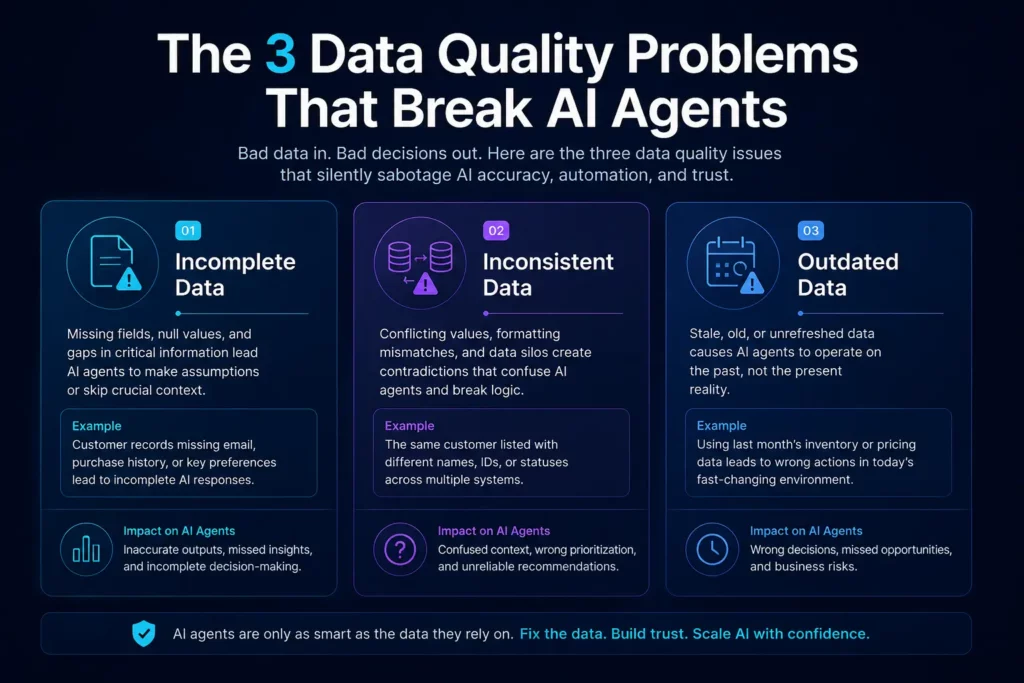
Not all data problems carry equal risk. When it comes to AI agents specifically, three patterns cause the most downstream damage.
Incomplete Data
Incomplete data means fields that should contain information are empty, null, or populated with placeholder values. For a human reading a report, an empty field is a flag to follow up. For an AI agent, it is often a signal to skip that record, make an assumption, or produce an output that excludes a critical variable.
In healthcare, incomplete patient records can lead an AI agent to generate clinical summaries that miss relevant diagnoses. In finance, incomplete transaction logs can cause automated reconciliation agents to produce reports that regulators will immediately question. The agent does not know what it does not know.
If your organization struggles with fragmented knowledge living across tools and teams, you already have a data completeness problem. Understanding how scattered knowledge silently sabotages AI performance is directly connected to why incomplete data causes agent failures.
Inconsistent Data
Inconsistency is more dangerous than incompleteness because it is harder to detect. Inconsistent data is present but contradictory. The same customer appears with three different company names across CRM, billing, and support systems. The same product has different SKU codes in two warehouses. The same employee has a start date in HR that does not match what is in payroll.
AI agents that draw from multiple data sources will encounter these contradictions and resolve them in ways that are technically logical but contextually wrong. The agent sees two valid records and chooses one. Nobody flags the discrepancy. The output looks clean. The decision is still wrong.
This is closely linked to the challenge of multiple versions of truth across enterprise systems. Organizations that have not resolved that problem at the data architecture level are not ready to run AI agents safely.
Outdated Data
An AI agent making decisions based on information that was accurate six months ago is making decisions in the past. Outdated data creates a time-lag between reality and what the agent believes to be true.
This is particularly acute in industries where conditions change quickly. Market data, inventory levels, regulatory requirements, contract terms, and customer preferences all shift. An agent relying on stale records will produce recommendations that are confidently wrong.
The connection between real-time data access and AI agent reliability deserves its own dedicated analysis, and it does. Organizations building AI agents without live data pipelines are setting themselves up for this exact failure mode.
Why Poor Data Quality Scales the Problem Instead of Containing It
Here is what makes this genuinely dangerous for leadership to understand. Human teams and poor data quality exist in a kind of friction that slows the damage. A sales manager spots that the customer record looks off. A finance analyst questions the number before it goes into the report. Manual verification acts as a natural buffer.
AI agents remove that buffer. When you automate a process that runs on poor data, you do not just replicate the existing error rate. You accelerate it. What was previously one wrong decision per week becomes one hundred wrong decisions per day, all consistent, all automated, and all downstream from the same corrupted source.
Scale is the thing that makes poor data quality existentially risky for AI deployments. Organizations that have not established an approval and review layer before AI-generated outputs reach decision-makers are particularly exposed. Automation without oversight turns a manageable data problem into a systemic one.
The damage compounds further when there are no metrics in place to measure AI performance. If you are not tracking the accuracy of your agent outputs against known baselines, poor data quality will go undetected for months. By the time someone notices, the contamination has spread across multiple systems, reports, and business decisions.
How to Assess Your Organization’s Data Quality Readiness Before Deploying AI Agents
Most data quality frameworks are designed for reporting and compliance. They are not built for the speed and autonomy of AI agent operations. Before you deploy any AI agent in a live business process, you need to run a different kind of assessment.
Start with your primary data sources. For every data asset an agent will access, ask four questions:
Who owns this data and is responsible for keeping it accurate? Organizations without clear AI ownership tend to have the same gap in data ownership. Nobody claims responsibility, so nobody maintains it.
How often is this data validated against a known source of truth? If the answer is quarterly or during audits, that cadence is too slow for autonomous agent operations.
What happens when a record is missing or contradictory? Is there a defined fallback, or does the system just make a choice? AI agents need explicit rules for handling data exceptions.
Is this data sourced from a live system or a static export? Static exports introduce version drift. Agents reading from exports are almost always working with data that is already partially outdated.
The answers to these four questions will tell you more about your AI readiness than any vendor briefing. Organizations that cannot answer them confidently are not in a position to deploy AI agents in production.
Building a Data Quality Foundation That AI Agents Can Actually Trust
Fixing data quality for AI operations is not a one-time cleanse. It is an ongoing architecture decision. Here is where to start.
Establish a single source of truth for every data domain that an AI agent will touch. This does not mean consolidating all data into one system. It means defining which system is authoritative for each data type, and making sure agents only read from that system. The documentation of that architecture matters just as much as the architecture itself. Undocumented workflows and unofficial data sources are how poor quality enters the pipeline quietly.
Build automated data validation into every pipeline that feeds an agent. This means schema checks, completeness checks, and anomaly detection that runs before data is served to the agent. Agents should never receive raw, unvalidated input from operational systems.
Instrument your agents to flag data-related failures explicitly. When an agent encounters a missing field, a value outside expected parameters, or a conflict between two sources, that event should be logged, categorized, and reviewed by a human. This is not just good practice. It is how you build the feedback loop that improves data quality over time.
Assign ownership. Every data domain feeding an AI agent needs a named person or team who is accountable for its accuracy. Without ownership, improvement discussions go nowhere. When something breaks, everyone points elsewhere.
Leadership driving AI adoption has to include leadership driving data ownership. If the CTO understands the data quality imperative but business unit heads are not committed to maintaining their data domains, the technical fixes will degrade quickly.
What Good Data Quality Enables Your AI Agents to Do
It is worth stepping back and making the positive case, because data quality conversations often stay stuck in risk and remediation.
When your AI agents operate on accurate, complete, and current data, their outputs become something your organization can actually rely on. Agents can close the loop between action and outcome. They can identify patterns that human analysts would miss. They can escalate anomalies correctly. They can produce recommendations that hold up to scrutiny.
That is the version of AI that most organizations are sold when they begin their journey. The reason they do not reach it is almost always data quality. The technology is capable. The data infrastructure is not ready.
Organizations that do invest in data quality before deployment see compounding returns. Every agent that operates reliably builds organizational confidence. That confidence makes the next deployment easier to approve, easier to scale, and easier to integrate into core business processes.
For CEOs and CTOs, the business case for data quality investment is not abstract. It is the difference between AI that generates demonstrable ROI and AI that generates expensive noise.
Poor Data Quality in the Context of the AI Agent Readiness Framework
This article covers sign twelve of the fifteen signs that your organization is not ready for AI agents. But it does not exist in isolation.
Poor data quality is often the downstream consequence of several other readiness gaps. When knowledge is scattered across teams and tools, data completeness suffers. When documentation does not reflect how work actually happens, the data that powers automated processes is built on false assumptions. When no one owns AI outcomes at the organizational level, data domains go unmaintained because there is no accountability structure.
Addressing poor data quality in isolation, without also examining the systemic gaps that produce it, is a short-term fix. If you have not yet worked through the earlier articles in the series, the ones covering scattered knowledge, documentation gaps, and real-time data access are the most directly relevant to what you have read here.
Also relevant: organizations that have not addressed security models built only for human users are often running agents that access data they should not, which compounds every data quality issue described in this article.
You can also review the original LinkedIn post on poor data quality quietly killing your AI agent strategy for additional context.
The Real Cost of Ignoring Data Quality in AI Deployments
Poor data quality is not a problem you discover after deploying AI agents. By that point, the damage is already compounding.
The organizations that succeed with AI at scale are the ones that treat data quality as a foundational requirement, not an afterthought. They assess their data before deployment. They build validation into their pipelines. They assign ownership. They measure accuracy and iterate on it.
The good news is that fixing data quality is entirely within your control. It does not require new technology. It requires commitment, ownership, and a clear process.
If you want to know where your organization stands across all fifteen readiness signs, start working through the AI Agent Readiness Series. Ysquare Technology helps enterprises identify and close these gaps before they become production failures. Reach out to the team on LinkedIn to start the conversation.
Read More
Ysquare Technology
12/06/2026

No Clear AI Ownership: The Silent Reason Your AI Agents Keep Breaking Down
Your AI agent goes live. It works. Then three weeks later, something quietly goes wrong. Outputs start drifting. A workflow sends the wrong notification. A report pulls stale data. And when you ask who is responsible for fixing it, everyone looks at someone else.
That is not a technology problem. That is an ownership problem.
No clear AI ownership in organizations is one of the most overlooked readiness gaps in enterprise AI today. You can build the most sophisticated agent in the world, but if nobody is accountable for its outcomes, it will fail. Slowly. Quietly. Expensively. This piece is part of our AI Agent Readiness Series, and it addresses Sign 11 from the framework: No Clear Ownership. If you have been nodding along to other signs in this series, like scattered knowledge silently sabotaging your AI or multiple versions of truth killing your data decisions, this one will hit close to home.
What Does No Clear AI Ownership Actually Mean?
Let’s be honest. Most companies deploy AI agents with a lot of excitement and very little clarity on who owns what after go-live.
No clear AI ownership means there is no single person or team formally accountable for an AI agent’s performance, outputs, or continuous improvement. It is not about who built it or who approved the budget. It is about who wakes up at 7 AM when the agent starts sending customers the wrong information.
Here is what this typically looks like in practice:
- The IT team says it is a business problem once it is deployed.
- The business team says it is a technical issue when something breaks.
- The vendor says it is working as intended.
- Leadership is waiting for a report that nobody is writing.
When issues remain unresolved because nobody is responsible for AI outcomes, the damage compounds every single day. That is the real cost of unclear accountability.
It connects directly to other readiness gaps too. If your documentation does not reflect how work actually happens, then your AI agent is working from a broken map. And if nobody owns the agent, nobody updates that map either.
Why AI Accountability in Business Is Not Optional
There is a phrase that applies perfectly here: ownership drives accountability. Without it, you do not have AI-assisted operations. You have AI-assisted chaos with better branding.
Think about what happens when an AI agent makes a wrong decision without a defined owner to catch it. If nobody validates outputs, mistakes can scale quickly. That is not a theoretical concern. In B2B environments where agents handle customer communications, data routing, or financial approvals, a single undetected error can trigger a cascade.
We covered the approval problem in depth in our piece on AI agents failing without an approval or review layer. But even a well-designed approval layer falls apart when no one is accountable for reviewing the reviews.
The real question is not whether your AI agent will ever make a mistake. It will. Every system does. The question is whether you have someone positioned to catch it, correct it, and prevent it from happening again. That person needs a title, a mandate, and the authority to act.
Primary keyword note: AI accountability in business is not a governance checkbox. It is the operating system that keeps your AI investments producing returns instead of producing liability.
The Real Cost of Undefined AI Accountability in Enterprise Teams
Let’s talk about what this actually costs you. Not in abstract terms but in operational reality.
1. Performance Degrades Without Anyone Noticing
AI agents are not static. Business context changes. Data sources evolve. Customer behavior shifts. Without an owner monitoring performance metrics, your agent keeps running on logic that was accurate six months ago and is quietly wrong today.
This connects directly to the measurement gap. When you are not tracking metrics for AI performance, you have no way to detect that your AI is underperforming until the damage is already done. Ownership without measurement is blind. Measurement without ownership is pointless.
2. Nobody Iterates. Performance Stagnates.
AI systems improve with feedback. That is not a nice-to-have. That is how they work. Without post-launch iteration driven by a named owner, your agent reaches a performance ceiling on day one and stays there.
We wrote about this specifically in the context of no post-launch iteration being a critical AI readiness gap. Without someone accountable for ongoing improvement, the agent becomes a legacy system the moment it goes live.
3. Conflicts Get Kicked Upstairs or Ignored
When your AI agent produces conflicting outputs across departments, someone needs the authority to resolve those conflicts. Without a defined owner, those conflicts sit in email threads and Slack messages for weeks. Meanwhile, the agent keeps producing wrong outputs at scale.
4. Security Gaps Go Unaddressed
An AI agent operates differently from a human employee. It does not get tired, distracted, or hesitant. When it has access to sensitive systems and nobody owns it, the access permissions set at launch never get reviewed. We explored this in our piece on security systems built only for humans failing AI agents. The ownership gap and the security gap feed each other.
What Good AI Ownership Structure Looks Like
Good AI ownership is not about adding another title to your org chart. It is about clarity. Here is what a functional ownership model looks like in practice.
Name One Person Per Agent
Every deployed AI agent should have exactly one named owner. Not a committee. Not a shared inbox. One person who is accountable for its performance, its outputs, and its ongoing improvement. That person should be close enough to the business process to understand context and senior enough to make decisions without escalating every change.
Define the Scope of Ownership
Ownership without scope creates confusion. Your AI owner needs to know exactly what they are responsible for. That includes performance benchmarks, error thresholds, data quality standards, and escalation paths when something breaks down.
This connects to the broader problem of real-time data access being a hidden readiness gap. An AI owner needs to know whether the agent is accessing live signals or stale data. That is a scope question before it becomes a technical question.
Build In Review Cycles
An AI agent should have a monthly or quarterly performance review the same way a business unit does. The owner leads this review, brings in the right stakeholders, and makes the call on what needs to change. Without structured review cycles, ownership is just a label.
Connect Ownership to Leadership Buy-in
Here is the catch. Ownership only works when leadership actually supports it. If the C-suite treats AI agents as a one-time deployment instead of a living system, your AI owner will be fighting a constant uphill battle. We covered this in our piece on leadership not driving AI adoption as a critical readiness failure. Adoption starts at the top. So does accountability.
How No Clear Ownership Connects to Other AI Readiness Gaps
Ownership is not an isolated problem. It sits at the intersection of almost every other AI readiness gap.
When you have multiple versions of truth creating conflicting data, an AI owner is the person who decides which version the agent trusts. Without that owner, the agent picks arbitrarily and nobody questions it.
When your documentation does not match how work actually happens, the owner is the person who ensures the agent is updated to reflect real processes, not documented ones.
When real-time data access is blocked or incomplete, the owner escalates that dependency and ensures the agent is not making decisions on outdated signals.
And when knowledge is scattered across silos and tools, the owner maps those silos and ensures the agent knows where to look.
The AI owner is, in effect, the connective tissue between your AI investment and the real business it is supposed to serve.
Steps to Fix the AI Ownership Gap Starting This Week
You do not need a six-month governance program to fix this. You need a few clear decisions made this week.
- Audit your deployed agents. List every AI system currently running in your organization. For each one, write down one name next to it. That person is the interim owner starting today.
- Define what ownership means. Create a one-page ownership charter per agent. Include performance KPIs, review frequency, escalation contacts, and change authority.
- Get a leadership sponsor. Every AI owner needs a leadership sponsor who will remove blockers and ensure the ownership role is respected cross-functionally.
- Set a 90-day review. Within 90 days of assigning an owner, conduct a formal performance review of the agent. This creates the first feedback loop and tests whether ownership is working.
- Tie ownership to outcomes. The AI owner should be measured on the outcomes the agent is supposed to deliver, not on whether the agent is running. Running is not the same as performing.
Is Your Organization Ready to Own Its AI Agents?
Most organizations are not. That is not a criticism. It is just the reality of where enterprise AI adoption is right now. The technology has moved faster than the organizational structures needed to govern it.
The good news is that this is one of the most solvable readiness gaps. It does not require new technology. It does not require a massive budget. It requires a decision: who owns this?
Make that decision for every AI agent you currently have running. Then make it mandatory before every future deployment. It sounds simple because it is. The complexity is in building the organizational culture where ownership is respected, supported, and measured.
If you are serious about AI agent readiness, start with our full readiness framework on the Ysquare Technology LinkedIn page. Each sign in the series connects to the others, and ownership is the thread that runs through all of them.
Final Thought: Ownership Is Not Bureaucracy. It Is How AI Scales.
Every time an AI agent fails quietly in a corner of your organization, it erodes trust in AI as a whole. Teams stop using it. Leadership pulls funding. The technology gets blamed when the problem was always structural.
Defining clear AI ownership is how you prevent that. It is how you build AI that improves month over month instead of decaying from launch day. It is how you turn a one-time deployment into a competitive advantage that compounds over time.
The question is not whether your AI can do the job. The question is whether your organization is structured to support it. Start with ownership. Everything else gets easier from there. And if you want a full picture of where your AI readiness stands today, explore our growing series covering all 15 signs, beginning with how scattered knowledge blocks AI agent performance.
Read More
Ysquare Technology
09/06/2026







