
AI Agent Documentation Gap: Why Most Implementations Fail

Let’s be honest you can’t teach an AI agent to do work that nobody can explain clearly. And that’s the exact trap most organizations walk into when deploying AI agents.
The promise sounds incredible: autonomous agents handling customer inquiries, processing approvals, managing workflows all while you sleep. But here’s the catch nobody mentions in the sales pitch: AI agents are only as good as the documentation they’re trained on. And in most enterprises, that documentation was written by humans, for humans, years ago and it hasn’t kept up with how work actually gets done today.
This is the documentation reality gap. Your official process says one thing. Your team does something completely different. And when you hand those outdated documents to an AI agent and tell it to “just follow the process,” you’re not automating efficiency. You’re scaling chaos.
The Documentation Crisis Nobody Wants to Talk About
Process documentation in most enterprises is in terrible shape. Not because anyone intended it that way but because documentation is treated as a compliance checkbox, not a living operational asset.
According to recent research, only 16% of organizations report having extremely well-documented workflows. That means 84% of companies are trying to deploy AI agents on shaky foundations. Even more telling: 49% of organizations admit that undocumented or ad-hoc processes impact their efficiency regularly.
Think about that for a second. Half of all businesses know their processes aren’t properly documented yet they’re still attempting to hand those same processes to autonomous AI systems and expecting success.
The numbers tell the brutal truth: between 80% and 95% of enterprise AI projects fail to deliver meaningful ROI. And while there are multiple reasons for failure, documentation mismatch sits at the core of most disasters.
Why Your Documentation Is Lying to Your AI Agent

Here’s what most people don’t realize: your company’s documentation wasn’t designed to be machine-readable. It was written by someone who understood the context, the history, the unwritten rules, and the exceptions that “everyone just knows.”
An employee reading your procurement policy understands that when it says “expenses over $5,000 require competitive bidding,” there’s an implicit exception for contract renewals with existing vendors. They know this because someone told them during onboarding, or they watched how their manager handled it, or they learned it through trial and error.
An AI agent reading that same policy? It sees an absolute rule. No exceptions. So when a $5,100 contract renewal comes through, the agent flags it as non-compliant — blocking a routine business transaction and creating unnecessary friction.
Scattered knowledge across multiple systems makes this problem exponentially worse. When your actual processes live in Slack threads, email chains, and the heads of employees who’ve been there for years, no amount of AI sophistication can bridge that gap.
The Configuration Drift Problem: When Documentation Ages Badly
Even when organizations start with good documentation, there’s another silent killer: configuration drift.
Your systems evolve. Workflows get updated. Teams find workarounds. Exceptions become standard practice. And nobody updates the documentation to reflect reality.
Pavan Madduri, a senior platform engineer at Grainger whose research focuses on governing agentic AI in enterprise IT, points to this as the core flaw in vendor promises that agents can “learn from observing existing workflows.” Observation without context creates incomplete understanding. The agent might replicate the workflow but it won’t understand why the workflow works that way, or when it should deviate.
ServiceNow and similar platforms tout their ability to learn from years of workflows that have run through their systems. The idea is elegant: no documentation required because the agent learns by watching. But that only works if those workflows were correct in the first place and if they haven’t drifted over time into something the original architects wouldn’t recognize.
Real-World Consequences of Documentation Mismatch
This isn’t a theoretical problem. Organizations are losing real money and credibility because their AI agents are following outdated or incomplete documentation.
New York City’s MyCity chatbot became infamous for giving businesses illegal advice telling them they could take workers’ tips, refuse tenants with housing vouchers, and ignore cash acceptance requirements. All violations of actual law. The bot confidently dispensed this misinformation for months after the problems were reported, because its documentation didn’t match legal reality.
Air Canada’s chatbot promised customers a discount policy that didn’t exist, and when a customer held the company to it, a Canadian court ruled that Air Canada was liable for what its agent said. The precedent is worth millions and it’s just the beginning.
In enterprise settings, the damage is often less public but equally expensive. An agent that misinterprets a procurement policy can lock up legitimate transactions. An agent that follows outdated security documentation can create vulnerabilities. An agent that executes based on old workflow diagrams can route approvals to the wrong people, delay critical decisions, or expose sensitive information to unauthorized users.
When your documentation lies about how processes actually work, AI agents don’t just fail — they fail at scale, with speed and consistency that human error could never match.
The Human-Readable vs. Machine-Readable Gap
Most enterprise documentation was written for humans who can:
- Infer context from incomplete information
- Recognize when a rule doesn’t apply to a specific situation
- Ask clarifying questions when something seems off
- Understand implied exceptions based on institutional knowledge
- Fill in gaps using common sense
AI agents can’t do any of that. They need documentation that is:
- Explicit — every exception documented, every edge case covered
- Complete — no gaps that require “just knowing” how things work
- Current — reflecting today’s reality, not last year’s process
- Unambiguous — one clear interpretation, not multiple valid readings
- Structured — organized in a way machines can parse and reference
The gap between these two documentation styles is where most AI agent failures originate. You hand the agent a human-friendly PDF and expect machine-level precision. It doesn’t work.
The Multi-Version Truth Problem
Here’s another pattern that kills AI implementations: when different teams maintain different versions of the “same” process.
Your HR handbook says remote work is encouraged. Your security policy says VPN access for customer data is restricted. Your IT operations guide has a third set of rules. An employee navigating this knows how to synthesize these documents and make a judgment call. An AI agent sees conflicting instructions and either freezes, picks one arbitrarily, or applies the wrong policy in the wrong context.
Why scattered knowledge silently sabotages your AI readiness comes down to this: when there’s no single source of truth, agents can’t learn what “correct” means. They see multiple versions of reality and have no reliable way to choose.
This creates what researchers call “context blindness” when agent responses don’t match your own documentation because the agent is pulling from outdated, incomplete, or conflicting sources.
How to Fix Your Documentation Before Deploying AI Agents
If you’re planning to deploy AI agents or already struggling with implementations that aren’t working — here’s what needs to happen:
Audit your actual processes, not your documented processes. Shadow employees doing the work. Record what they actually do, not what the handbook says they should do. The delta between those two is your documentation debt and it needs to be paid before AI can help.
Map where your process documentation lives. Is it in SharePoint? Confluence? Google Docs? Slack channels? Tribal knowledge? If it’s scattered across multiple systems and formats, consolidate it. Agents need a single, authoritative source they can query reliably.
Version control everything. Your documentation should have the same rigor as your code. Track changes. Review updates. Deprecate outdated versions clearly. An agent following last year’s documentation is worse than an agent with no documentation because it’s confidently wrong.
Document exceptions explicitly. That “everyone just knows” exception? Write it down. Define when it applies. Provide examples. AI agents don’t have institutional memory. If it’s not in the documentation, it doesn’t exist.
Test your documentation with someone who’s never done the job. If they can follow your process documentation from start to finish without asking clarifying questions, you’re close to machine-readable. If they get stuck, confused, or need to make judgment calls based on context clues, your documentation isn’t ready for AI.
Implement continuous documentation maintenance. Every time a process changes, the documentation changes. Not “when someone gets around to it” immediately. Treat documentation like production code: changes require reviews, approvals, and deployment tracking.
The Strategic Question Most Organizations Skip
Here’s the question vendors won’t ask you, but you need to ask yourself: can you describe your critical processes completely and accurately, without relying on “that’s just how we’ve always done it”?
If the answer is no or if there’s significant disagreement among your team about what the “right” process actually is you’re not ready for AI agents. You don’t have a technology problem. You have an organizational clarity problem.
And that’s actually good news, because organizational clarity problems can be fixed. They just need to be fixed before you hand your processes to an autonomous system and tell it to execute at scale.
Building Documentation That Agents Can Actually Use
The future of enterprise documentation isn’t just writing better documents. It’s designing documentation systems that serve both human and machine readers effectively.
This means:
- Structured formats that machines can parse (not just PDFs)
- Linked data connecting related policies, exceptions, and edge cases
- Version history that allows rollback when changes cause problems
- Validation layers that catch conflicts between related documents
- Feedback loops that flag when documented processes diverge from observed behavior
Some organizations are experimenting with AI agents to help maintain documentation using agents to identify drift, flag inconsistencies, and suggest updates based on observed workflows. It’s recursive, yes: using AI to fix the documentation that AI needs to function. But it’s also pragmatic.
Eugene Petrenko documented how 16 AI agents helped refactor documentation for other AI agents to use. The key insight? Documentation quality improved dramatically when evaluated by AI readers instead of human assumptions about what AI needs. The metrics were clear: documents scored 7.0 before refactoring jumped to 9.0 after because the team finally understood what “machine-readable” actually meant.
The Real Cost of Documentation Debt
Organizations rushing to deploy AI agents without fixing their documentation foundations are making an expensive bet. They’re wagering that AI sophistication can overcome organizational chaos. It can’t.
Poor documentation doesn’t become less of a problem when you add AI. It becomes a bigger one. As one practitioner put it: “If you have clean, structured, well-maintained processes, AI makes those faster and easier. If you have chaos, undocumented workarounds, inconsistent data, AI compounds that too. Runs your broken process faster and at higher volume than you ever could manually.”
The agent doesn’t resolve the documentation gap. It scales it.
This is why only 26% of organizations that have implemented AI agents rate them as “completely successful.” The technology works. But the foundations don’t.
What Success Actually Looks Like
Organizations that succeed with AI agents share a common pattern: they invested in documentation excellence before they deployed the first agent.
Snowflake took a data-first approach to AI implementation. Instead of rushing to deploy AI tools across the organization, the company built robust data infrastructure and documentation that AI systems could trust. David Gojo, head of sales data science at Snowflake, emphasizes that successful AI deployments require “accurate, timely information that AI systems can trust.”
The result? AI tools that sales teams actually adopted because the recommendations were backed by reliable data and clear documentation, not generating false confidence from incomplete information.
Your Next Move
If you’re considering AI agents, start with an honest documentation audit. Not the audit where you check if documentation exists the audit where you test if it reflects reality.
Walk through your critical processes. Compare what’s documented to what actually happens. Identify the gaps. Quantify the drift. And be brutally honest about whether your organization can articulate its processes clearly enough for a machine to follow them.
Because here’s the hard truth: if your documentation doesn’t match reality, your AI agents will fail. Not eventually. Immediately. And the failure will be loud, expensive, and difficult to fix after the fact.
The good news? This is fixable. Documentation debt can be paid down. Processes can be clarified. Knowledge can be consolidated. But it needs to happen before you deploy agents — not after they’ve already scaled your broken processes to catastrophic proportions.
The question isn’t whether your organization will invest in documentation quality. The question is whether you’ll do it before or after your AI agents fail publicly.
Frequently Asked Questions
1. What is the documentation reality gap in AI agent implementation?
The documentation reality gap occurs when your organization's official process documentation doesn't match how work is actually performed. This mismatch causes AI agents to follow outdated or incomplete instructions, leading to errors, inefficiencies, and failed implementations. While humans can bridge this gap using context and institutional knowledge, AI agents execute based solely on what's documented.
2. Why do most enterprise AI projects fail despite advanced technology?
Between 80-95% of enterprise AI projects fail primarily due to organizational readiness issues, not technology limitations. Poor documentation quality, scattered knowledge across systems, undocumented workflows, and the gap between documented processes and actual practices create foundations too unstable for AI agents to operate effectively. Only 16% of organizations have extremely well-documented workflows.
3. How does configuration drift impact AI agent performance?
Configuration drift happens when systems, workflows, and processes evolve over time but documentation isn't updated to reflect these changes. AI agents trained on outdated documentation will execute obsolete processes confidently, creating inefficiencies or errors. Unlike humans who adapt to changes organically, agents need documentation that accurately reflects current reality.
4. What's the difference between human-readable and machine-readable documentation?
Human-readable documentation relies on context, implied exceptions, and institutional knowledge that employees understand intuitively. Machine-readable documentation must be explicit, complete, unambiguous, and structured so AI agents can parse and execute processes without human interpretation. Most enterprise documentation is written for humans and requires significant restructuring for AI consumption.
5. How can organizations audit their documentation for AI readiness?
Conduct a documentation audit by shadowing employees performing critical processes and comparing their actual workflows to documented procedures. Test documentation by having someone unfamiliar with the process follow it without asking clarifying questions. Identify gaps, exceptions, and tribal knowledge that exist in practice but not in documentation. Measure the delta between "what the handbook says" and "what people actually do."
6. What are the real-world risks of deploying AI agents with poor documentation?
Organizations face legal liability (as seen in the Air Canada chatbot case), regulatory violations (like NYC's MyCity chatbot giving illegal business advice), operational disruptions from blocked transactions, security vulnerabilities from following outdated protocols, and reputational damage. AI agents scale these problems rapidly because they execute incorrect processes with speed and consistency that human error never could.
7. How does scattered knowledge across multiple systems sabotage AI implementations?
When process documentation lives across Slack threads, email chains, SharePoint, Confluence, Google Docs, and employee memories, AI agents cannot access a single source of truth. This creates conflicting instructions, incomplete context, and the "multiple versions of truth" problem where agents cannot determine which documentation is authoritative, leading to inconsistent or incorrect execution.
8. What documentation practices are essential before deploying AI agents?
Implement version control for all documentation, consolidate knowledge into single authoritative sources, document all exceptions and edge cases explicitly, establish continuous documentation maintenance workflows, create structured formats that machines can parse, test documentation with unfamiliar users, and maintain linked data connecting related policies and procedures.
9. Can AI agents help improve documentation quality?
Yes — some organizations use AI agents to maintain documentation by identifying drift between documented and observed processes, flagging inconsistencies across related documents, and suggesting updates. This creates a recursive improvement loop where AI helps create the documentation quality that AI systems need to function effectively. Eugene Petrenko documented how 16 AI agents improved documentation scores from 7.0 to 9.0 by evaluating machine-readability.
10. What's the first step organizations should take to prepare documentation for AI agents?
Start with an honest audit that tests whether documentation reflects current reality, not just whether it exists. Walk through critical processes, compare documented procedures to actual workflows, identify gaps and drift, and quantify the documentation debt. Address this organizational clarity problem before deploying AI agents — fixing documentation after agents have scaled broken processes is far more expensive and disruptive.

Poor Data Quality Is Silently Killing Your AI Agent Strategy
Your AI agents are not the problem. Your data is.
Most organizations investing heavily in AI automation hit the same invisible wall. The tools are purchased, the agents are deployed, and the dashboards look impressive. But the outputs are wrong. Decisions are off. The team loses trust in the system within weeks.
Here is the real reason: poor data quality is quietly undermining everything your AI agents are supposed to do. It is not a technology failure. It is a data failure that was always there, just waiting for an autonomous system to expose it at scale.
This is the twelfth sign in the AI Agent Readiness Series, which examines fifteen critical gaps that prevent organizations from running AI agents reliably. If your AI agents are producing unreliable outputs, inconsistent results, or decisions that nobody trusts, data quality is almost certainly the root cause. Let us get into exactly why, and what you can do about it.
What Poor Data Quality Actually Means for AI Agents
Most executives interpret data quality as a technical concern they delegate to their data teams. That is understandable, but it misses the real business exposure.
For AI agents, data quality is not just about clean spreadsheets or well-labelled databases. It covers every piece of information an agent reads, references, or acts on when executing a task. That means CRM records with inconsistent customer names, ERP entries with missing cost codes, product catalogues with outdated pricing, and patient records with duplicate entries across systems.
AI agents do not verify data before they use it. They cannot pause and say this looks wrong. They process what they are given and produce outputs accordingly. When the input is corrupted, incomplete, or contradictory, the agent delivers garbage outputs at the speed of automation.
The old principle applies perfectly here: garbage in equals garbage out. The difference is that a human analyst might catch an anomaly before it becomes a decision. An AI agent running at scale will not.
Here is what that looks like in practice. An agent managing procurement approvals reads outdated supplier pricing data and commits to orders at rates that are no longer valid. An agent handling patient scheduling pulls from a record that has not been updated since a system migration, and books appointments for inactive patients. An agent producing financial summaries aggregates figures from two databases that use different fiscal calendar definitions.
None of these failures are caused by the AI being wrong. They are caused by the data being wrong. Understanding this distinction is the first step toward fixing it.
The Three Most Dangerous Forms of Poor Data Quality in AI Deployments
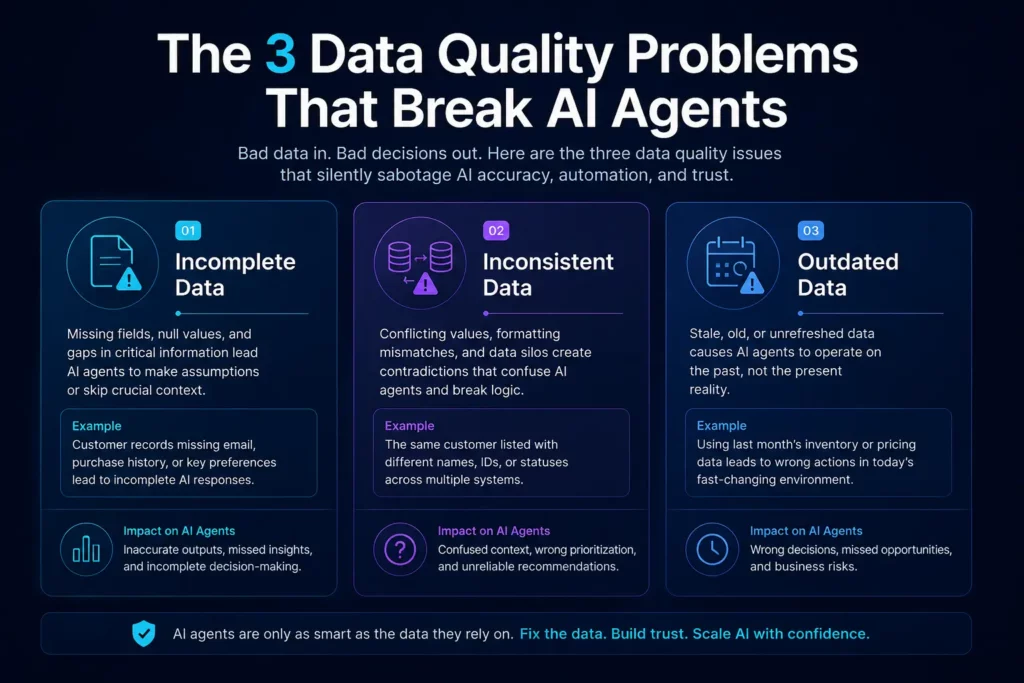
Not all data problems carry equal risk. When it comes to AI agents specifically, three patterns cause the most downstream damage.
Incomplete Data
Incomplete data means fields that should contain information are empty, null, or populated with placeholder values. For a human reading a report, an empty field is a flag to follow up. For an AI agent, it is often a signal to skip that record, make an assumption, or produce an output that excludes a critical variable.
In healthcare, incomplete patient records can lead an AI agent to generate clinical summaries that miss relevant diagnoses. In finance, incomplete transaction logs can cause automated reconciliation agents to produce reports that regulators will immediately question. The agent does not know what it does not know.
If your organization struggles with fragmented knowledge living across tools and teams, you already have a data completeness problem. Understanding how scattered knowledge silently sabotages AI performance is directly connected to why incomplete data causes agent failures.
Inconsistent Data
Inconsistency is more dangerous than incompleteness because it is harder to detect. Inconsistent data is present but contradictory. The same customer appears with three different company names across CRM, billing, and support systems. The same product has different SKU codes in two warehouses. The same employee has a start date in HR that does not match what is in payroll.
AI agents that draw from multiple data sources will encounter these contradictions and resolve them in ways that are technically logical but contextually wrong. The agent sees two valid records and chooses one. Nobody flags the discrepancy. The output looks clean. The decision is still wrong.
This is closely linked to the challenge of multiple versions of truth across enterprise systems. Organizations that have not resolved that problem at the data architecture level are not ready to run AI agents safely.
Outdated Data
An AI agent making decisions based on information that was accurate six months ago is making decisions in the past. Outdated data creates a time-lag between reality and what the agent believes to be true.
This is particularly acute in industries where conditions change quickly. Market data, inventory levels, regulatory requirements, contract terms, and customer preferences all shift. An agent relying on stale records will produce recommendations that are confidently wrong.
The connection between real-time data access and AI agent reliability deserves its own dedicated analysis, and it does. Organizations building AI agents without live data pipelines are setting themselves up for this exact failure mode.
Why Poor Data Quality Scales the Problem Instead of Containing It
Here is what makes this genuinely dangerous for leadership to understand. Human teams and poor data quality exist in a kind of friction that slows the damage. A sales manager spots that the customer record looks off. A finance analyst questions the number before it goes into the report. Manual verification acts as a natural buffer.
AI agents remove that buffer. When you automate a process that runs on poor data, you do not just replicate the existing error rate. You accelerate it. What was previously one wrong decision per week becomes one hundred wrong decisions per day, all consistent, all automated, and all downstream from the same corrupted source.
Scale is the thing that makes poor data quality existentially risky for AI deployments. Organizations that have not established an approval and review layer before AI-generated outputs reach decision-makers are particularly exposed. Automation without oversight turns a manageable data problem into a systemic one.
The damage compounds further when there are no metrics in place to measure AI performance. If you are not tracking the accuracy of your agent outputs against known baselines, poor data quality will go undetected for months. By the time someone notices, the contamination has spread across multiple systems, reports, and business decisions.
How to Assess Your Organization’s Data Quality Readiness Before Deploying AI Agents
Most data quality frameworks are designed for reporting and compliance. They are not built for the speed and autonomy of AI agent operations. Before you deploy any AI agent in a live business process, you need to run a different kind of assessment.
Start with your primary data sources. For every data asset an agent will access, ask four questions:
Who owns this data and is responsible for keeping it accurate? Organizations without clear AI ownership tend to have the same gap in data ownership. Nobody claims responsibility, so nobody maintains it.
How often is this data validated against a known source of truth? If the answer is quarterly or during audits, that cadence is too slow for autonomous agent operations.
What happens when a record is missing or contradictory? Is there a defined fallback, or does the system just make a choice? AI agents need explicit rules for handling data exceptions.
Is this data sourced from a live system or a static export? Static exports introduce version drift. Agents reading from exports are almost always working with data that is already partially outdated.
The answers to these four questions will tell you more about your AI readiness than any vendor briefing. Organizations that cannot answer them confidently are not in a position to deploy AI agents in production.
Building a Data Quality Foundation That AI Agents Can Actually Trust
Fixing data quality for AI operations is not a one-time cleanse. It is an ongoing architecture decision. Here is where to start.
Establish a single source of truth for every data domain that an AI agent will touch. This does not mean consolidating all data into one system. It means defining which system is authoritative for each data type, and making sure agents only read from that system. The documentation of that architecture matters just as much as the architecture itself. Undocumented workflows and unofficial data sources are how poor quality enters the pipeline quietly.
Build automated data validation into every pipeline that feeds an agent. This means schema checks, completeness checks, and anomaly detection that runs before data is served to the agent. Agents should never receive raw, unvalidated input from operational systems.
Instrument your agents to flag data-related failures explicitly. When an agent encounters a missing field, a value outside expected parameters, or a conflict between two sources, that event should be logged, categorized, and reviewed by a human. This is not just good practice. It is how you build the feedback loop that improves data quality over time.
Assign ownership. Every data domain feeding an AI agent needs a named person or team who is accountable for its accuracy. Without ownership, improvement discussions go nowhere. When something breaks, everyone points elsewhere.
Leadership driving AI adoption has to include leadership driving data ownership. If the CTO understands the data quality imperative but business unit heads are not committed to maintaining their data domains, the technical fixes will degrade quickly.
What Good Data Quality Enables Your AI Agents to Do
It is worth stepping back and making the positive case, because data quality conversations often stay stuck in risk and remediation.
When your AI agents operate on accurate, complete, and current data, their outputs become something your organization can actually rely on. Agents can close the loop between action and outcome. They can identify patterns that human analysts would miss. They can escalate anomalies correctly. They can produce recommendations that hold up to scrutiny.
That is the version of AI that most organizations are sold when they begin their journey. The reason they do not reach it is almost always data quality. The technology is capable. The data infrastructure is not ready.
Organizations that do invest in data quality before deployment see compounding returns. Every agent that operates reliably builds organizational confidence. That confidence makes the next deployment easier to approve, easier to scale, and easier to integrate into core business processes.
For CEOs and CTOs, the business case for data quality investment is not abstract. It is the difference between AI that generates demonstrable ROI and AI that generates expensive noise.
Poor Data Quality in the Context of the AI Agent Readiness Framework
This article covers sign twelve of the fifteen signs that your organization is not ready for AI agents. But it does not exist in isolation.
Poor data quality is often the downstream consequence of several other readiness gaps. When knowledge is scattered across teams and tools, data completeness suffers. When documentation does not reflect how work actually happens, the data that powers automated processes is built on false assumptions. When no one owns AI outcomes at the organizational level, data domains go unmaintained because there is no accountability structure.
Addressing poor data quality in isolation, without also examining the systemic gaps that produce it, is a short-term fix. If you have not yet worked through the earlier articles in the series, the ones covering scattered knowledge, documentation gaps, and real-time data access are the most directly relevant to what you have read here.
Also relevant: organizations that have not addressed security models built only for human users are often running agents that access data they should not, which compounds every data quality issue described in this article.
You can also review the original LinkedIn post on poor data quality quietly killing your AI agent strategy for additional context.
The Real Cost of Ignoring Data Quality in AI Deployments
Poor data quality is not a problem you discover after deploying AI agents. By that point, the damage is already compounding.
The organizations that succeed with AI at scale are the ones that treat data quality as a foundational requirement, not an afterthought. They assess their data before deployment. They build validation into their pipelines. They assign ownership. They measure accuracy and iterate on it.
The good news is that fixing data quality is entirely within your control. It does not require new technology. It requires commitment, ownership, and a clear process.
If you want to know where your organization stands across all fifteen readiness signs, start working through the AI Agent Readiness Series. Ysquare Technology helps enterprises identify and close these gaps before they become production failures. Reach out to the team on LinkedIn to start the conversation.
Read More

Ysquare Technology
12/06/2026

No Clear AI Ownership: The Silent Reason Your AI Agents Keep Breaking Down
Your AI agent goes live. It works. Then three weeks later, something quietly goes wrong. Outputs start drifting. A workflow sends the wrong notification. A report pulls stale data. And when you ask who is responsible for fixing it, everyone looks at someone else.
That is not a technology problem. That is an ownership problem.
No clear AI ownership in organizations is one of the most overlooked readiness gaps in enterprise AI today. You can build the most sophisticated agent in the world, but if nobody is accountable for its outcomes, it will fail. Slowly. Quietly. Expensively. This piece is part of our AI Agent Readiness Series, and it addresses Sign 11 from the framework: No Clear Ownership. If you have been nodding along to other signs in this series, like scattered knowledge silently sabotaging your AI or multiple versions of truth killing your data decisions, this one will hit close to home.
What Does No Clear AI Ownership Actually Mean?
Let’s be honest. Most companies deploy AI agents with a lot of excitement and very little clarity on who owns what after go-live.
No clear AI ownership means there is no single person or team formally accountable for an AI agent’s performance, outputs, or continuous improvement. It is not about who built it or who approved the budget. It is about who wakes up at 7 AM when the agent starts sending customers the wrong information.
Here is what this typically looks like in practice:
- The IT team says it is a business problem once it is deployed.
- The business team says it is a technical issue when something breaks.
- The vendor says it is working as intended.
- Leadership is waiting for a report that nobody is writing.
When issues remain unresolved because nobody is responsible for AI outcomes, the damage compounds every single day. That is the real cost of unclear accountability.
It connects directly to other readiness gaps too. If your documentation does not reflect how work actually happens, then your AI agent is working from a broken map. And if nobody owns the agent, nobody updates that map either.
Why AI Accountability in Business Is Not Optional
There is a phrase that applies perfectly here: ownership drives accountability. Without it, you do not have AI-assisted operations. You have AI-assisted chaos with better branding.
Think about what happens when an AI agent makes a wrong decision without a defined owner to catch it. If nobody validates outputs, mistakes can scale quickly. That is not a theoretical concern. In B2B environments where agents handle customer communications, data routing, or financial approvals, a single undetected error can trigger a cascade.
We covered the approval problem in depth in our piece on AI agents failing without an approval or review layer. But even a well-designed approval layer falls apart when no one is accountable for reviewing the reviews.
The real question is not whether your AI agent will ever make a mistake. It will. Every system does. The question is whether you have someone positioned to catch it, correct it, and prevent it from happening again. That person needs a title, a mandate, and the authority to act.
Primary keyword note: AI accountability in business is not a governance checkbox. It is the operating system that keeps your AI investments producing returns instead of producing liability.
The Real Cost of Undefined AI Accountability in Enterprise Teams
Let’s talk about what this actually costs you. Not in abstract terms but in operational reality.
1. Performance Degrades Without Anyone Noticing
AI agents are not static. Business context changes. Data sources evolve. Customer behavior shifts. Without an owner monitoring performance metrics, your agent keeps running on logic that was accurate six months ago and is quietly wrong today.
This connects directly to the measurement gap. When you are not tracking metrics for AI performance, you have no way to detect that your AI is underperforming until the damage is already done. Ownership without measurement is blind. Measurement without ownership is pointless.
2. Nobody Iterates. Performance Stagnates.
AI systems improve with feedback. That is not a nice-to-have. That is how they work. Without post-launch iteration driven by a named owner, your agent reaches a performance ceiling on day one and stays there.
We wrote about this specifically in the context of no post-launch iteration being a critical AI readiness gap. Without someone accountable for ongoing improvement, the agent becomes a legacy system the moment it goes live.
3. Conflicts Get Kicked Upstairs or Ignored
When your AI agent produces conflicting outputs across departments, someone needs the authority to resolve those conflicts. Without a defined owner, those conflicts sit in email threads and Slack messages for weeks. Meanwhile, the agent keeps producing wrong outputs at scale.
4. Security Gaps Go Unaddressed
An AI agent operates differently from a human employee. It does not get tired, distracted, or hesitant. When it has access to sensitive systems and nobody owns it, the access permissions set at launch never get reviewed. We explored this in our piece on security systems built only for humans failing AI agents. The ownership gap and the security gap feed each other.
What Good AI Ownership Structure Looks Like
Good AI ownership is not about adding another title to your org chart. It is about clarity. Here is what a functional ownership model looks like in practice.
Name One Person Per Agent
Every deployed AI agent should have exactly one named owner. Not a committee. Not a shared inbox. One person who is accountable for its performance, its outputs, and its ongoing improvement. That person should be close enough to the business process to understand context and senior enough to make decisions without escalating every change.
Define the Scope of Ownership
Ownership without scope creates confusion. Your AI owner needs to know exactly what they are responsible for. That includes performance benchmarks, error thresholds, data quality standards, and escalation paths when something breaks down.
This connects to the broader problem of real-time data access being a hidden readiness gap. An AI owner needs to know whether the agent is accessing live signals or stale data. That is a scope question before it becomes a technical question.
Build In Review Cycles
An AI agent should have a monthly or quarterly performance review the same way a business unit does. The owner leads this review, brings in the right stakeholders, and makes the call on what needs to change. Without structured review cycles, ownership is just a label.
Connect Ownership to Leadership Buy-in
Here is the catch. Ownership only works when leadership actually supports it. If the C-suite treats AI agents as a one-time deployment instead of a living system, your AI owner will be fighting a constant uphill battle. We covered this in our piece on leadership not driving AI adoption as a critical readiness failure. Adoption starts at the top. So does accountability.
How No Clear Ownership Connects to Other AI Readiness Gaps
Ownership is not an isolated problem. It sits at the intersection of almost every other AI readiness gap.
When you have multiple versions of truth creating conflicting data, an AI owner is the person who decides which version the agent trusts. Without that owner, the agent picks arbitrarily and nobody questions it.
When your documentation does not match how work actually happens, the owner is the person who ensures the agent is updated to reflect real processes, not documented ones.
When real-time data access is blocked or incomplete, the owner escalates that dependency and ensures the agent is not making decisions on outdated signals.
And when knowledge is scattered across silos and tools, the owner maps those silos and ensures the agent knows where to look.
The AI owner is, in effect, the connective tissue between your AI investment and the real business it is supposed to serve.
Steps to Fix the AI Ownership Gap Starting This Week
You do not need a six-month governance program to fix this. You need a few clear decisions made this week.
- Audit your deployed agents. List every AI system currently running in your organization. For each one, write down one name next to it. That person is the interim owner starting today.
- Define what ownership means. Create a one-page ownership charter per agent. Include performance KPIs, review frequency, escalation contacts, and change authority.
- Get a leadership sponsor. Every AI owner needs a leadership sponsor who will remove blockers and ensure the ownership role is respected cross-functionally.
- Set a 90-day review. Within 90 days of assigning an owner, conduct a formal performance review of the agent. This creates the first feedback loop and tests whether ownership is working.
- Tie ownership to outcomes. The AI owner should be measured on the outcomes the agent is supposed to deliver, not on whether the agent is running. Running is not the same as performing.
Is Your Organization Ready to Own Its AI Agents?
Most organizations are not. That is not a criticism. It is just the reality of where enterprise AI adoption is right now. The technology has moved faster than the organizational structures needed to govern it.
The good news is that this is one of the most solvable readiness gaps. It does not require new technology. It does not require a massive budget. It requires a decision: who owns this?
Make that decision for every AI agent you currently have running. Then make it mandatory before every future deployment. It sounds simple because it is. The complexity is in building the organizational culture where ownership is respected, supported, and measured.
If you are serious about AI agent readiness, start with our full readiness framework on the Ysquare Technology LinkedIn page. Each sign in the series connects to the others, and ownership is the thread that runs through all of them.
Final Thought: Ownership Is Not Bureaucracy. It Is How AI Scales.
Every time an AI agent fails quietly in a corner of your organization, it erodes trust in AI as a whole. Teams stop using it. Leadership pulls funding. The technology gets blamed when the problem was always structural.
Defining clear AI ownership is how you prevent that. It is how you build AI that improves month over month instead of decaying from launch day. It is how you turn a one-time deployment into a competitive advantage that compounds over time.
The question is not whether your AI can do the job. The question is whether your organization is structured to support it. Start with ownership. Everything else gets easier from there. And if you want a full picture of where your AI readiness stands today, explore our growing series covering all 15 signs, beginning with how scattered knowledge blocks AI agent performance.
Read More
Ysquare Technology
09/06/2026

No Post-Launch Iteration: The Silent Reason Your AI Agents Stop Improving
You spent months building your AI agent. The demo worked beautifully. Leadership approved the rollout. And then you launched. That was six months ago. Here is the question nobody in your organization is asking: is that agent actually getting better?
Most of the time, the honest answer is no. Not because the technology failed, but because the team moved on. There is a deeply ingrained assumption in enterprise AI deployments that launch is the finish line. It is not. Launch is where the real work begins. And skipping the post-launch iteration phase is one of the most expensive mistakes organizations make with AI agents today.
This is part of a broader pattern we have been tracking across enterprise AI readiness. If you have already read about how scattered knowledge silently sabotages your AI agents, you will recognize the theme: the problems that kill AI agent performance are rarely about the model itself. They are, instead, about the organizational infrastructure around it. And no post-launch iteration is one of the most overlooked gaps of all.
The Production Reality
The Composio AI Agent Report 2025 found that 67% of organizations report measurable gains from agent pilots, yet only 10% successfully scale to production. The gap does not sit in the technology. It lives, instead, in what happens, or more accurately what does not happen, after the agent goes live.
What No Post-Launch Iteration Actually Means for Your AI Agents
Let us be clear about what we are talking about. Post-launch iteration for AI agents is the ongoing process of monitoring real-world performance, collecting feedback, identifying failure patterns, and making targeted improvements. In other words, it is the cycle that turns a static deployment into a system that learns and compounds value over time.
Without it, your AI agent becomes frozen at the capability level it had on launch day. That is a serious problem, because the world around it does not stay frozen. Business processes shift, data patterns change, user needs evolve, and edge cases multiply. As a result, what performed well in testing starts encountering situations it was never prepared for in production.
The degradation is rarely dramatic, which is precisely what makes it so dangerous. A real-world case documented by SaaStr describes a team that deployed an AI agent, watched it perform well, and then moved on to other projects. Four months later, the agent had quietly stopped ingesting new data. Moreover, it kept running and kept producing outputs that looked plausible, but was operating entirely on stale information. The team only caught it when results started feeling slightly off. Not wrong enough to trigger alarms. Just a little out of step with reality.
This is the operational signature of an AI agent with no iteration loop. Rather than crashing visibly, it just slowly stops being useful.
Furthermore, the same dynamic is explored in depth in our LinkedIn article on why post-launch iteration is the silent reason your AI agents underperform, which looks at how this pattern shows up across enterprise deployments of every size.
Why AI Agent Performance Stagnation Is Now a Business Risk
The scale of the problem is becoming impossible to ignore. According to a June 2025 Gartner press release, over 40% of agentic AI projects will be canceled by the end of 2027, with escalating costs, unclear business value, and inadequate risk controls as the primary reasons. What does inadequate risk control look like in practice? Often it looks exactly like an agent running in production with no feedback loop and no mechanism for improvement.
McKinsey’s 2025 State of AI report reinforces the picture: fewer than 20% of AI pilots scale to production within 18 months, and only 39% of organizations report any enterprise-level EBIT impact from AI. Consequently, the organizations that are generating real returns are not necessarily the ones with the best models. They are the ones that have built processes for continuous improvement after launch.
Beyond that, research from Lemma, a YCombinator F25 company building continuous learning infrastructure for AI agents, found that agent performance can drop approximately 40% within weeks of deployment. This happens as real-world input drift introduces user behaviors and edge cases that were not present in testing. That is not a model failure. That is a process failure, and it is entirely preventable with the right iteration infrastructure in place.
The Compounding Cost
High-volume agents processing thousands of transactions daily see measurable accuracy improvements within 30 to 45 days when a feedback loop is active. Without one, however, performance flatlines or silently degrades from day one. The longer you wait to implement iteration, the more ground you have to recover.
The Five Ways No Post-Launch Iteration Damages AI Agent Readiness
Understanding the specific mechanisms of performance stagnation helps you make the case internally for why iteration infrastructure is not optional. Here are the five most common patterns we see.
1. Distribution Shift Goes Undetected
Your agent was trained and tested on a specific snapshot of your business data. The moment it goes live, however, the real world starts diverging from that snapshot. New product lines, updated workflows, seasonal demand shifts, and new customer segments all push the agent away from its original frame of reference. Distribution shift is the technical term for this divergence, and without continuous monitoring, it remains invisible until the agent starts making decisions that feel wrong but are hard to explain.
The connection to your broader data environment is critical here. If your organization already struggles with multiple versions of truth creating conflicting data across systems, distribution shift compounds that problem at speed.
2. Edge Cases Accumulate Without Resolution
No pre-launch test suite captures every real-world scenario. Edge cases are inevitable, and therefore the question is not whether your agent will encounter them but whether your organization has a mechanism for identifying, analyzing, and resolving them. Without an iteration process, those edge cases pile up and are never addressed. Each one represents a user who received a wrong or unhelpful response. At scale, this erodes trust in ways that are very difficult to recover from.
3. Business Process Changes Outpace the Agent
Organizations are not static. Processes change, policies update, and teams restructure constantly. As a result, an AI agent trained on how your business operated six months ago becomes increasingly misaligned with how it operates today. This is especially dangerous when the agent is handling workflows that touch customers, finance, or compliance. We have covered the upstream version of this problem in our piece on undocumented workflows and AI automation failures. The same dynamic plays out post-launch when iteration is absent.
4. No Feedback Means No Learning Signal
Research from Dust’s continuous improvement framework is clear on this point: if there is no clear owner for an agent and no time allocated to iterate, agents simply do not improve. Feedback that is never collected cannot drive learning. In addition, many organizations have no structured process for gathering input from the people who interact with the agent every day, whether they are employees or customers.
Because of this, organizations that have no system for measuring AI agent performance after deployment are essentially operating blind. You cannot improve what you are not measuring.
5. Security and Compliance Drift
An agent that handled sensitive data appropriately at launch may not remain compliant as regulations evolve and your data environment changes. Security models built for static systems need regular review when applied to autonomous agents. This is not theoretical: the AI Incidents Database reports that AI-related incidents rose 21% from 2024 to 2025. Furthermore, many of those incidents involve agents that were operating outside their original governance parameters without anyone noticing.
For a detailed look at why security frameworks designed for human operators fail AI agents, our blog post on security models built only for humans creating AI agent vulnerabilities covers the specific gaps that post-launch monitoring needs to close.
How Post-Launch Iteration Actually Works in Practice
Here is the thing: building an iteration loop for your AI agent does not require a separate engineering team or a six-month project. It requires clarity about four things.
Continuous Monitoring with Automated Evaluation
You need a system that scores agent responses against accuracy, helpfulness, and task completion on an ongoing basis, not just in pre-launch testing. Leading evaluation frameworks now support LLM-as-a-judge scoring, where a secondary model reviews a sample of production outputs and generates quality scores. Performance is graphed over time, and alerts fire when quality degrades. As a result, you find out from a dashboard rather than from an angry user or a manager who noticed something felt off.
Structured Feedback Collection from Real Users
The people using your agent every day are your best source of iteration signal. Building a lightweight, structured mechanism for them to flag unhelpful or incorrect responses turns anecdotal frustration into actionable data. Fortunately, the feedback does not need to be complex. A simple thumbs-down with a category tag is enough to surface patterns.
Beyond flagging errors, your approval and review layer for AI outputs becomes a source of iteration data, not just a quality gate. Every human review generates a signal about where the agent’s judgment diverged from the expected outcome.
Targeted, Incremental Updates
The most common mistake in post-launch iteration is trying to overhaul the agent when a targeted edit would suffice. The Dust framework recommends starting with the top failure mode surfaced by your monitoring, making a surgical change to instructions, data sources, or parameters, testing with a small group, and then rolling out broadly. Small, targeted changes are easier to test and, equally important, easier to roll back if something breaks.
This is the iteration mentality that software engineering teams have applied for decades. AI agents deserve the same discipline. Ship, measure, learn, and improve. Then repeat.
Ownership and Accountability
No iteration loop survives without a named owner. Someone in your organization needs to be responsible for the agent’s ongoing performance, with time explicitly allocated to the iteration process. Without this structure, feedback goes nowhere and insights gather dust. This gap is directly linked to the leadership ownership gap that keeps AI agents underperforming across enterprises, a pattern our piece on leadership not driving AI adoption examines from the top down.
What Your AI Agent Ecosystem Looks Like Without Iteration
Let us paint the picture honestly. Six months after launch, an AI agent with no iteration process typically looks like this:
- Performance has plateaued or quietly declined from its peak at launch
- Users have developed workarounds for the edge cases the agent handles poorly
- Business process changes have introduced misalignments the agent has no way to know about
- The team that built the agent has moved on to the next project
- Nobody has a clear picture of what the agent is actually doing at scale
This is not a hypothetical. It is the operational reality for a significant portion of enterprise AI deployments today. The Composio 2025 report’s finding that only 10% of organizations successfully scale agent pilots to production reflects both a pre-launch problem and a post-launch one. Many organizations reach production and then fail to sustain it because there is no iteration infrastructure keeping the agent aligned with reality.
The data quality dimension makes this even more acute. If your agent is operating on real-time data access gaps that leave it working from outdated information, the absence of post-launch iteration means those gaps compound rather than get resolved. Consequently, the agent becomes increasingly disconnected from the current state of your business.
Building the Case for Post-Launch Iteration Internally
If you are a technology leader reading this, you likely already know the iteration gap exists in your organization. The challenge, however, is making the case for dedicated iteration resources in an environment where the initial deployment already consumed significant budget and attention.
Frame It as a Cost of Stagnation, Not a Cost of Iteration
Here is the framing that tends to land with business stakeholders. Your AI agent is a revenue or efficiency-linked system. Its current performance level represents a baseline, and therefore every week you do not iterate is a week you are leaving potential improvement on the table. Every edge case that accumulates represents a customer interaction or process step where the agent is actively failing. The cost of not iterating is not zero. It is the cumulative sum of all those missed improvements and unresolved failures.
Anchor to ROI Evidence
McKinsey data shows that organizations achieving real ROI from AI are not necessarily using better models. Instead, they are applying better operational discipline to the systems they have. The 5.8x ROI on AI investment within 14 months that McKinsey’s research documents is not achieved by deploying and forgetting. It is achieved by deploying, measuring, iterating, and compounding gains over time.
Include Documentation Teams in the Conversation
Beyond the commercial case, the technical teams building documentation for your agent also need to be part of this discussion. If your documentation does not reflect how AI agents actually make decisions in the field, iteration becomes much harder because you have no reliable baseline to measure against.
Practical Steps to Start Your Post-Launch Iteration Process Today
You do not need to wait for a perfect system. You need to start. Here is a practical sequence that works for organizations at every stage of AI maturity.
Step 1: Assign an Agent Owner
Name a single person responsible for the ongoing performance of each production AI agent. While this does not need to be a full-time role, it needs to be a named accountability. Without ownership, everything else in this list will fail to stick.
Step 2: Define Your Performance Baseline
Before you can track improvement, you need to know where you are starting. Pull your current task completion rates, user satisfaction signals, and error patterns. If you do not have this data yet, the first iteration sprint should focus on instrumentation: getting the logging and monitoring in place so you have something to measure against.
Step 3: Run a Weekly Feedback Review
Set a recurring thirty-minute review where the agent owner looks at the feedback and error data from the previous week. Identify the top failure pattern. Then make one targeted improvement, not a full rebuild. Test it, observe the impact, and repeat next week.
Step 4: Connect Your Iteration Loop to Your Data Infrastructure
The iteration process only works if the agent is operating on accurate, current data. If scattered knowledge across your organization is limiting what your AI agents can access, your iteration loop needs to include data quality improvements, not just prompt tuning.
Step 5: Make Iteration Part of Your AI Governance Framework
Finally, post-launch iteration should not be an informal practice that depends on individual initiative. It should be a documented process with scheduled reviews, defined metrics, and governance sign-off for significant changes. This is what turns a good AI deployment into a sustainable one.
The Real Question Is Not Whether to Iterate. It Is How Long You Can Afford Not To.
Here is a perspective shift worth sitting with. Every enterprise software system your organization depends on gets maintained, updated, and improved on a regular cycle. Nobody deploys a CRM or an ERP and then never touches it again. Yet that is exactly the treatment many organizations give their AI agents, and then they wonder why the results plateau.
AI agents are not set-and-forget tools. They are living systems that operate in changing environments and need ongoing attention to stay aligned with your business reality. Therefore, the organizations that will generate lasting ROI from AI are the ones building the discipline of continuous iteration into their deployment model from day one.
Gartner’s warning that over 40% of agentic AI projects will be canceled by end of 2027 is not a verdict on AI technology. Rather, it is a verdict on AI deployment practices. The technology works. The processes around it are, however, still catching up. Post-launch iteration is one of the places where closing that gap makes the most immediate difference.
If you are building AI agents at scale and want to make sure iteration is built into your readiness model from the ground up, connect with the Ysquare Technology team on LinkedIn to explore how we approach enterprise AI agent deployment with long-term performance in mind.
Read More
Ysquare Technology
05/06/2026







