
The Hidden Costs of Running AI Agents Without an Approval Layer

You’ve deployed AI agents. They’re running workflows, responding to customers, processing data, and making decisions around the clock. Sounds like progress.
But here’s the question most leaders don’t ask until it’s too late: who is checking what those agents actually do?
If the answer is “nobody” or worse, “the agent itself” you have a problem that is quietly compounding every single day.
No approval or review layer is one of the most dangerous gaps in any AI deployment. It’s not a technical flaw. It’s a governance failure. And unlike a bug you can patch overnight, the damage it causes often spreads across customer relationships, compliance records, and business data long before anyone notices.
Let’s break down exactly what this means, why it matters, and what you can do about it.
What “No Approval or Review Layer” Means for AI Agents
An approval and review layer is a structured checkpoint — built into your AI agent’s workflow — that pauses, flags, or routes outputs before they become actions.
Without it, the process looks like this:
Input → AI processing → Output → Immediate action
No pause. No validation. No human judgment applied at any point in the chain.
That might seem efficient. In reality, it means every hallucination, misinterpretation, and policy error your agent produces goes straight into your operations — into your customer communications, your databases, your financial processes — without a single filter between the mistake and the consequence.
AI agents are powerful precisely because they move fast and operate at scale. But speed without oversight doesn’t make your business faster. It makes your errors faster.
This issue also doesn’t exist in isolation. If your agents are already working from scattered knowledge spread across disconnected systems, or relying on undocumented workflows that live only in your team’s heads, removing the review layer from an already fragile foundation is like removing the brakes from a vehicle you’re not entirely sure is steering correctly.
Why AI Decision Checkpoints Matter More Than Most People Realize
Here’s what most people miss: the risk isn’t a single catastrophic failure. It’s thousands of small, compounding errors that no one catches because no system is looking for them.
A human employee who makes a mistake gets corrected within hours. Their manager notices, the process adapts, and the scope of damage is contained. An AI agent running flawed logic makes the same mistake on every interaction every transaction, every customer response, every data entry until someone happens to investigate.
By that point, the error isn’t a mistake. It’s a pattern baked into your operations.
The consequences tend to cluster around three areas:
Customer trust: Incorrect information delivered confidently at scale damages your brand in ways that are very hard to walk back. Customers don’t distinguish between “the AI got it wrong” and “the company got it wrong.”
Compliance exposure: Regulators don’t accept “the agent did it” as a defense. If your AI is making decisions in areas governed by financial, healthcare, or data privacy regulations, the absence of human oversight is a liability not a technical footnote.
Data integrity: AI agents connected to live systems can write bad data into records, trigger incorrect downstream processes, and corrupt operational data that other teams and systems depend on. Without a review layer, that contamination spreads silently.
Real-World Case Study: What Happened When Air Canada Skipped the Review Layer
Company: Air Canada What happened:
In November 2022, a customer named Jake Moffatt visited Air Canada’s website after the death of his grandmother. He interacted with the airline’s AI-powered chatbot and asked about bereavement fares. The chatbot told him he could purchase a full-price ticket now and apply retroactively for a bereavement discount within 90 days of purchase. He followed that advice, bought the ticket, and submitted the refund request.
Air Canada denied the claim. Their actual policy didn’t permit retroactive bereavement fare applications. When challenged, the airline argued the chatbot was effectively a “separate legal entity” responsible for its own outputs not a position the court found remotely credible.
Key Outcome:
On February 14, 2024, British Columbia’s Civil Resolution Tribunal ruled against Air Canada in Moffatt v. Air Canada (2024 BCCRT 149). The airline was ordered to pay compensation. The tribunal stated plainly: “the chatbot is still just a part of Air Canada’s website.” The company could not distance itself from what its own AI said to a paying customer.
Shortly after the ruling, the chatbot was removed from Air Canada’s website entirely.
The governance failure:
The chatbot produced an answer that contradicted documented company policy. There was no review mechanism to catch that contradiction before it reached the customer. One incorrect AI output created a legal case, a public relations problem, and a forced product shutdown all of which were entirely preventable with a simple validation layer.
Source: Moffatt v. Air Canada, 2024 BCCRT 149 — McCarthy.ca
The Data Backs This Up
This isn’t an isolated incident. The pattern is consistent and well-documented.
Stanford’s 2025 AI Index recorded 233 AI-related incidents in 2024 — a 56% increase from the previous year. A significant proportion of those incidents involved autonomous AI outputs that weren’t reviewed before they caused harm.
Gartner predicts that over 40% of agentic AI projects will be cancelled before reaching maturity by the end of 2027, with poor governance structures including the absence of review checkpoints identified as the primary driver of failure.
McKinsey research found that 80% of organizations have already encountered risky AI agent behaviours in production, including unauthorized data access and incorrect outputs at scale. Most of those organizations lacked a formal review process at the time.
The organizations extracting measurable value from AI aren’t the ones deploying fastest. They’re the ones building oversight infrastructure that makes their agents trustworthy enough to operate at scale.
A related problem compounds this further. When agents work with conflicting data from multiple sources of truth, or without access to real-time information that reflects current conditions, the error rate climbs — and the urgency of a review layer increases proportionally.
How to Know If Your Organization Has This Problem
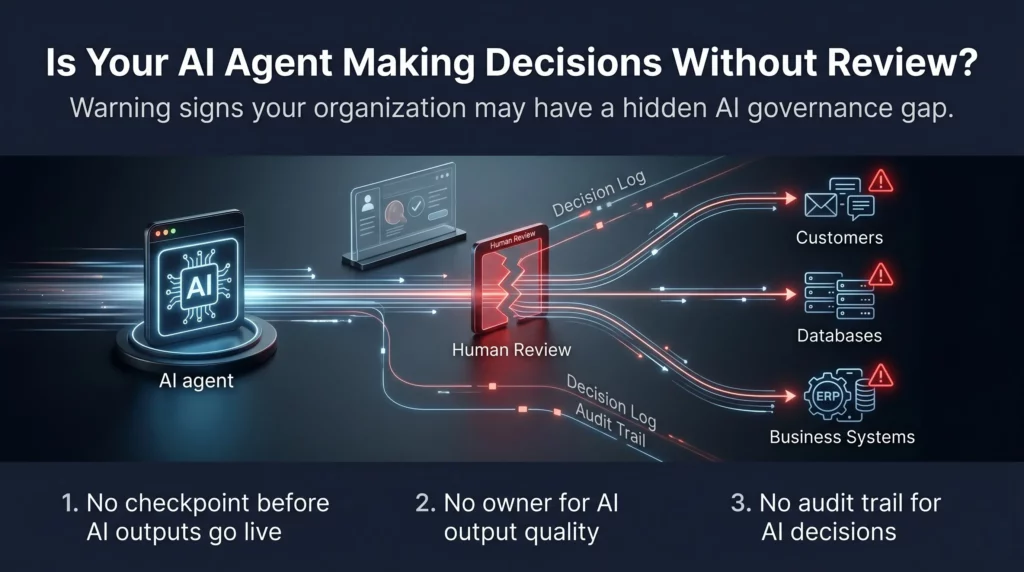
You don’t always need a tribunal ruling to identify this gap. These are the practical warning signs:
- AI outputs reach customers, databases, or downstream systems with no intermediate checkpoint
- There is no defined owner of AI output quality in your organization
- You don’t have a process for routing high-risk or low-confidence AI decisions to a human reviewer
- You’ve discovered errors in AI outputs after they’d already caused a business problem — not before
- Your team has no escalation path when an agent produces something unexpected
- You cannot produce an audit trail that explains why a specific AI decision was made
If several of those describe your current setup, you’re not in a minority. But you are in a position where one poorly-timed error could become a very public problem.
How to Build an Approval and Review Layer That Works at Scale
Adding oversight to your AI workflows doesn’t mean hiring people to manually read every output. It means designing governance that’s proportional to risk.
Start with a risk-tiered approach
Not every AI decision carries the same exposure. Map your agent’s outputs into three tiers:
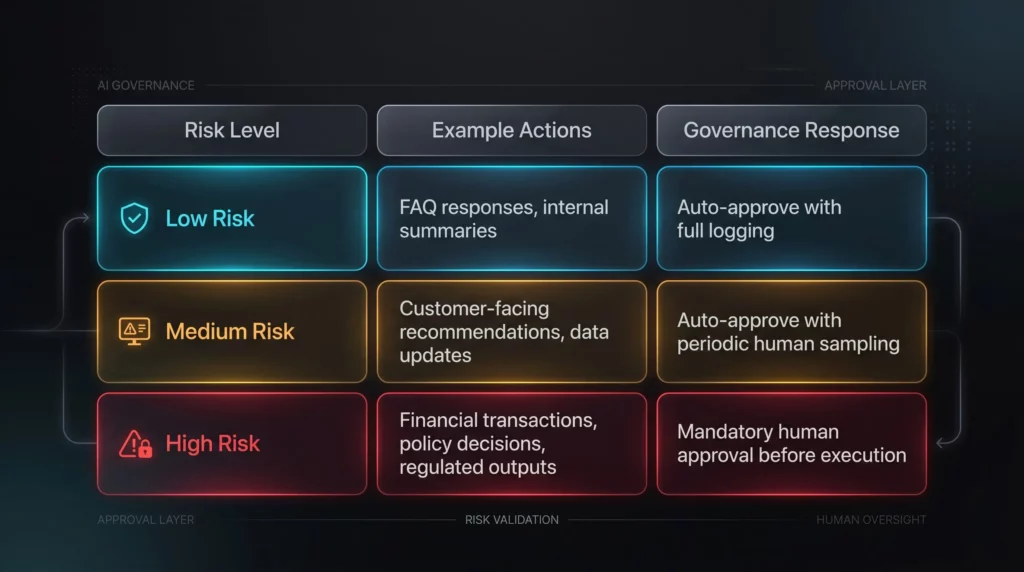
This structure lets your agents move fast on routine decisions while adding friction exactly where the stakes are highest.
Build automated flagging into your workflows
Define the conditions that trigger a review — before a human needs to catch it manually:
- The agent’s confidence score falls below a defined threshold
- The output involves sensitive data or a significant transaction value
- The request falls outside the agent’s defined operational scope
- The output contradicts a documented company policy
- The input contains ambiguous or conflicting signals
When those conditions are met, the output routes to a review queue. The agent continues with everything else. You keep the efficiency. You add the accountability.
Create governance records, not just logs
There’s an important distinction here. A transaction log tells you what your agent did. A governance record tells you why it was authorized to do it — under which rules, with what input, at what confidence level, and who or what validated the decision.
When regulators, auditors, or customers ask why something happened, they’re asking for the governance record. Most organizations currently only have the log. That gap matters.
Assign ownership
Someone in your organization needs to own AI output quality. Not as a side responsibility attached to a developer’s role — as a defined accountability. If an agent makes an error, someone should be the person who answers for it internally. That clarity drives better governance design from the start.
What Getting This Right Actually Looks Like
According to Cleanlab’s 2025 AI Agents in Production report, regulated enterprises the organizations that have been forced to think carefully about AI oversight are outperforming their unregulated peers on reliability, adoption, and measurable ROI. They’re not slower because of their governance structures. They’re more trusted, which means their teams use the tools more, which means they extract more value.
The insight here isn’t that oversight slows AI down. It’s that oversight is what allows organizations to trust their AI enough to actually expand its use. Agents without review layers don’t just create legal exposure they create institutional hesitancy. Teams who’ve seen an AI error cause a problem become cautious about relying on AI at all.
If your documentation doesn’t accurately reflect how your processes actually work, a review layer also helps your team catch the gaps that feed bad outputs in the first place — turning each flagged error into a learning signal rather than just a cost.
The Bottom Line
AI agents are not inherently risky. Unchecked AI agents are.
The difference between a deployment that builds trust and one that creates liability isn’t the sophistication of the model. It’s whether someone or some system is verifying what the agent does before the consequences are irreversible.
The organizations winning with AI right now are the ones who understood early that governance isn’t a constraint on performance. It’s the foundation of it.
If you’re deploying agents without an approval and review layer, you’re not moving faster than your competitors. You’re accumulating risk that will eventually surface as a cost.
Ready to Build AI Agents Your Business Can Actually Rely On?
At Ysquare Technology, we help enterprise leaders design and deploy AI agent systems built for real-world operations — with the governance, oversight, and accountability structures that scale without breaking.
Explore more in this series:
Frequently Asked Questions
1. What is an approval and review layer for AI agents?
An approval and review layer is a governance checkpoint built into AI agent workflows. It ensures that AI outputs — especially high-risk or high-impact decisions — are validated by a human or rule-based system before they're executed or shared. It's the mechanism that keeps autonomous AI accountable.
2. Why do AI agents need human oversight and review checkpoints?
AI agents can produce incorrect, biased, or policy-violating outputs without any intent to do so. Without human oversight, those errors reach customers and systems at scale before anyone catches them. Review checkpoints contain the damage from individual errors and create audit trails that protect the organization legally and operationally.
3. What happens when AI agents operate without an approval layer?
Without an approval layer, every AI error reaches its destination unfiltered. Mistakes that would normally be caught in review compound across hundreds or thousands of interactions. The result is scaled damage to customer trust, data integrity, and regulatory standing — as the Air Canada case demonstrated in 2024.
4. How does a human-in-the-loop system work with AI agents?
A human-in-the-loop (HITL) system routes specific AI outputs to a human reviewer before they're finalized. Triggers typically include low confidence scores, high-risk decision types, sensitive data, or unusual input patterns. The AI continues processing everything else autonomously, preserving efficiency while adding oversight where it matters.
5. What is the difference between an AI audit trail and an AI governance record?
An audit trail records what an AI agent did — the action, the output, the timestamp. A governance record explains why the agent was authorized to take that action — the rules applied, the input received, the confidence level, and the validation chain. Regulators and auditors ask for governance records, not just logs.
6. Which industries face the highest risk from AI agents without review layers?
Financial services, healthcare, insurance, legal services, and aviation carry the highest exposure, because AI errors in those sectors can directly cause financial harm, health risks, or legal liability. However, any industry where AI outputs reach customers or drive significant business decisions carries meaningful risk without proper oversight.
7. How do you build a tiered approval workflow for AI agents?
Categorize your AI agent's outputs by the impact if they're wrong. Low-risk outputs — like internal summaries or FAQ responses — can be auto-approved with logging. Medium-risk outputs should be periodically sampled by humans. High-risk outputs — financial transactions, policy decisions, regulated outputs — require mandatory human approval before execution.
8. Does adding an AI review layer slow down automation?
Not if it's designed correctly. Selective oversight — where only high-risk decisions require human review — keeps the vast majority of interactions fully automated. The goal isn't to review everything. It's to review the right things. Most AI workflows can maintain near-complete automation while adding meaningful accountability exactly where it's needed.
9. What does the EU AI Act require for human oversight of AI agents?
The EU AI Act, in force since August 2024, requires documented human oversight for high-risk AI systems. This includes AI used in credit decisions, employment screening, and essential services. Organizations must maintain decision documentation, evidence trails, and an authorization chain that can be audited on demand.
10. How can I tell if my organization is missing an AI approval and review layer?
The most direct signal is that AI outputs reach production, customers, or live systems without any human checkpoint. Supporting signs include: no defined escalation path for unexpected agent behaviour, inability to produce a governance record for AI decisions, no clear ownership of AI output quality, and errors that were only discovered after causing a downstream problem.

AI Agent Cost Monitoring: Why Your AI Agents Are Spending More Than You Think
You approved the AI agent rollout. The demos looked impressive. The pilot numbers justified the investment. And then, a few quarters later, your finance team flagged an infrastructure report that made no sense.
The costs had tripled. Quietly. Without warning.
Nobody caught it because nobody was watching. No dashboards. No spending thresholds. No assigned owner. Just agents running continuously, calling APIs, processing data, and generating costs that nobody reviewed until the numbers became impossible to ignore.
This is Sign 15 in Ysquare’s AI Agent Readiness Series: No Cost Monitoring. It is one of the most financially damaging gaps an enterprise can leave open, and it is far more common than most technology leaders realize. The organizations that have scaled AI successfully share one consistent trait: they treat cost visibility with the same discipline they apply to performance visibility. Non-negotiable, real-time, and clearly owned.
If your organization is running AI agents without a financial monitoring layer, this article is written for you.
What Is AI Agent Cost Monitoring and Why Does It Matter?
AI agent cost monitoring is the ongoing practice of tracking, attributing, and managing every expense generated by your AI agents in real time. It is not the same as reviewing your monthly cloud bill. It goes much deeper than that.
Most enterprise leaders think about AI costs as a single line item. In reality, AI agent spending is distributed across several distinct categories, each with its own behavior, scaling pattern, and risk profile.
The Four Cost Categories Every Enterprise Must Track
- API call volume and token consumption sit at the core of most AI agent costs. Every query an agent sends to a large language model carries a cost based on the number of tokens processed. Agents that run in loops, handle large documents, retry failed tasks, or manage complex multi-step workflows can generate tens of thousands of API calls daily. At a small scale this is invisible. At production scale it becomes a material expense.
- Compute and orchestration infrastructure is the second layer. Running agent workflows requires compute resources for the orchestration layer, memory storage, intermediate processing, and any real-time data retrieval operations. These costs scale with usage and are often underestimated during the planning phase because pilot environments do not reflect production load.
- Third-party tool and data integration costs form the third category. AI agents almost always connect to external services: CRM platforms, document repositories, communication tools, analytics databases, and external data providers. Many of these connections carry usage-based pricing. The more an agent operates, the higher these integration costs climb.
- Rework and failure costs are the most underappreciated cost driver of all. When agents operate on poor quality data, lack clear operational boundaries, or encounter workflow failures, they do not stop cleanly. They retry. They loop. They call the same APIs repeatedly trying to complete a task that was never going to succeed with the input they were given. Every failed cycle is a cost with no corresponding value.
This last point connects to something we have covered in detail in our article on how poor data quality silently inflates AI agent costs. The financial impact of data quality problems does not stay in the data layer. It flows directly into your AI agent operating costs.
Why Enterprise AI Spending Spirals Without Monitoring
The question executives often ask is a fair one: how does this happen in organizations that already have financial controls in place? The answer is that AI agent deployments create a set of conditions that make cost overruns unusually easy to miss.
The Pilot Phase Creates a False Baseline
Every AI agent deployment starts with a pilot. The pilot is intentionally limited in scope, controlled in volume, and closely watched by a small team. Costs during this phase are predictable and manageable. Leadership sees a favorable cost-to-output ratio, approves full-scale deployment, and moves on.
What nobody accounts for is how dramatically the cost structure changes when agents move from pilot to production. A pilot running 50 tasks per day becomes a production system running 5,000 tasks per day. API costs that were negligible become a significant operating expense. Compute costs that fit comfortably within a development budget grow into a line item that requires active management.
Because no monitoring infrastructure was built during the pilot, the production cost reality only becomes visible when a billing report arrives. By that point, weeks or months of unnecessary spending have already occurred.
No Ownership Means No Accountability
Untracked costs and unclear ownership almost always appear together. When no single person or team is financially accountable for AI agent operations, cost overruns have no natural owner to surface them. They drift. Quietly and continuously.
This is a pattern we have written about directly in our article on no clear AI ownership in organizations. The absence of ownership is not just a governance problem. It is a financial risk that compounds over time.
Decentralized Deployments Fragment Visibility
In most large enterprises, AI agent deployments do not happen exclusively through a central technology team. Individual business units, product teams, and developers spin up their own agent workflows. Some of these are formally approved. Many are not. Each operates within its own budget silo, invisible to any consolidated view of AI spending.
This fragmentation means that even when some AI costs are tracked, the total picture is never complete. Finance teams work from partial data. Technology leaders make investment decisions without understanding the real baseline. And the gap between tracked and actual AI spending widens every quarter.
The Business Consequences of Unmonitored AI Agent Costs
Understanding that the problem exists is one thing. Understanding what it actually costs the business is what should compel leadership to act.
Financial Planning Becomes Unreliable
When AI agent costs are not tracked in real time, finance teams cannot build reliable forecasts. They work from estimates based on pilot data that no longer reflects production reality. Annual budget cycles incorporate assumptions that are often off by a wide margin.
The downstream effect is that technology investment decisions become harder to defend. CFOs ask for cost justification. Technology leaders cannot provide it because the data does not exist in a usable form. This creates a cycle where AI investments face more scrutiny, approvals slow down, and the organization loses momentum at exactly the moment it should be accelerating.
You Cannot Prove Return on Investment
AI agents are supposed to generate value that exceeds their cost. But when costs are unmonitored, that equation cannot be verified from either side. You know what the agents are doing. You may even have a sense of the productivity gains they are delivering. But you cannot close the financial loop because the denominator is unknown.
This matters most when leadership is trying to make the case for expanding AI investment. Without accurate cost data, the ROI argument rests on anecdote rather than numbers. That is a fragile foundation for decisions that require board-level approval or significant budget reallocation.
We explored this challenge directly in our article on no metrics for AI performance. Cost is one of the most important metrics in that framework, and the absence of it undermines every other measurement your organization tries to build.
Inefficient Agents Run Indefinitely
Here is something that surprises many technology leaders when they first implement cost monitoring: a meaningful portion of their AI agent spending is being consumed by agents that are operating inefficiently. Not failing completely. Not producing zero output. Just performing at a fraction of their potential efficiency while consuming far more resources than they should.
An agent querying an oversized data source for every task when a filtered subset would do. An agent running a six-step reasoning chain for questions that require two steps. An agent retrying a failed integration call repeatedly instead of failing gracefully and escalating.
Without cost monitoring, none of these inefficiencies produce a visible signal. The agents keep running. The costs keep accumulating. And the optimization opportunity goes unrecognized until someone builds the visibility layer that makes it apparent.
Vendor and Infrastructure Negotiations Happen Without Data
Every organization running AI agents at scale will eventually need to negotiate contracts. API pricing agreements. Infrastructure volume commitments. SaaS integration terms. These negotiations require accurate usage data to be effective.
Organizations without cost monitoring walk into these conversations blind. They cannot demonstrate their actual usage patterns. They cannot make the case for volume-based discounts. They cannot identify which pricing structures favor their specific workload profile. The result is consistently worse commercial outcomes than would have been possible with proper visibility.
What Effective AI Agent Cost Monitoring Requires
Getting cost monitoring right is not about deploying a single tool and calling it done. It requires building a set of interconnected capabilities that together create genuine financial visibility.
Real-Time Cost Visibility Across Every Agent
The foundation is a real-time view of what every AI agent is spending, broken down by agent, by workflow, by business unit, and by time period. This is the same principle that drives mature organizations to build real-time data access for operational AI systems. Delayed data is not operational data. If your cost view is 30 days old, you are managing by looking in the rear-view mirror.
This visibility layer needs to capture the full cost picture: API call costs, compute consumption, integration usage, and where possible, the cost impact of errors and retries.
Proactive Alerts Before Costs Become Problems
Dashboards tell you what has happened. Alerts tell you what is happening right now. Build threshold-based alerts that trigger when a specific agent exceeds its daily spending limit, when API call volume spikes beyond expected ranges, or when error rates climb in ways that suggest retry loops are inflating costs.
The target is to surface a cost anomaly within hours, not at the end of a billing period. An alert triggered on day two of an unexpected cost spike saves far more than one triggered on day thirty.
Clear Cost Attribution by Team and Business Unit
Enterprise AI deployments span multiple teams. Cost monitoring needs to reflect that reality. Each business unit deploying AI agents should receive regular visibility into their specific spending, compared against their approved budget and against the business outcomes their agents are producing.
This structure does two things simultaneously. It gives central leadership a consolidated view of total AI spending. And it gives individual business units the information they need to manage their own usage responsibly. Both matter.
Cost Per Outcome Metrics
Total spending tells you how much your AI agents cost. Cost per outcome tells you whether that spending is justified. Track cost per task completed, cost per successful outcome, and cost per unit of measurable business value delivered.
These metrics make it possible to compare efficiency across different agents and workflows. They surface the cases where an agent is technically working but operating at a cost that does not make business sense. And they create the financial vocabulary that technology leaders need to have credible conversations with finance and executive leadership.
If your organization has already addressed the security model for AI agents and the approval and review layer for AI outputs, cost per outcome metrics are the natural next layer of operational maturity.
Building an AI Cost Monitoring Framework: A Practical Path for Leaders
Theory is useful. Action is better. Here is a practical five-step path that CEOs, CTOs, and technology leaders can follow to build real financial visibility into their AI agent operations.
Step 1: Run a Full AI Agent Spending Audit
Before you can monitor, you need to know what you are monitoring. Start by identifying every AI agent your organization is running, including those deployed by individual teams outside formal approval processes. Map each agent to its primary cost drivers: API usage, compute, storage, and third-party integrations.
This audit almost always surfaces significantly more spending than technology or finance teams expected. That discovery is not a failure. It is the first step toward control.
Step 2: Assign a Named Cost Owner for Every Agent Deployment
Every AI agent deployment needs a financial owner. This does not require creating new roles. In most cases the right owner is already the person or team responsible for the business function the agent serves. What changes is making that financial accountability explicit: they are responsible for monitoring spending, responding to alerts, and participating in monthly cost reviews.
Step 3: Build Monitoring Infrastructure Before You Scale
This is the principle that most organizations get backwards. They scale first and build monitoring later. The monitoring retrofit is always harder, more expensive, and slower than building it into the deployment from the start.
If you have a pilot ready to go to production, build the monitoring layer first. Instrument your cost tracking. Configure your alerts. Establish your reporting cadence. Then scale. By the time the production system is running at full volume, you have complete financial visibility from day one.
Step 4: Establish Cost Budgets at the Agent and Workflow Level
A global AI budget is not enough. You need cost budgets at the individual agent and workflow level. These budgets should reflect the expected value each agent delivers. A high-value workflow justifies a higher cost ceiling. A routine administrative automation needs a tighter constraint.
These budgets become the reference points against which your monitoring alerts are calibrated. They also create the accountability structure that cost owners need to manage their deployments responsibly.
Step 5: Run Monthly Cost and Efficiency Reviews
Cost monitoring data is only valuable if it drives decisions. Schedule a monthly review where cost owners present their spending actuals against budget, identify their highest-cost agents, and bring a perspective on whether those costs are proportionate to the value delivered.
This review is also the right place to surface opportunities to optimize. Agents running undocumented workflows that may be driving unnecessary activity or processing redundant data from multiple conflicting sources are often the highest-cost, lowest-efficiency systems in the portfolio. Monthly reviews make these visible before they become entrenched.
The Mistakes That Undermine AI Cost Monitoring Programs
Even organizations that commit to cost monitoring often fall into patterns that reduce its effectiveness. These are the most common.
Monitoring Infrastructure Costs but Missing API and Integration Costs
Infrastructure compute is the most visible AI cost because it appears on cloud billing statements. But in many enterprise AI deployments, API call costs and third-party integration fees can become as important as infrastructure costs. An organization that only monitors compute spending may be missing a large part of its actual AI expenditure while assuming it has full visibility.
Build monitoring that captures every cost category, not just the one that is easiest to see.
Building Alerts That Nobody Acts On
Alert systems fail when they generate too much noise or when alerts have no assigned owner. Both conditions lead to the same outcome: alerts get ignored, the monitoring system develops a reputation for being unhelpful, and cost overruns continue unchecked despite the infrastructure that was supposed to prevent them.
Every alert needs an owner. Every category of alert needs a defined response protocol. And the alert threshold configuration needs regular review to ensure it is generating actionable signals, not background noise.
Treating the Monitoring Setup as Permanent
AI agent usage patterns evolve continuously. New workflows get added. Agent behavior changes as models are updated or prompt configurations shift. Seasonal usage patterns create periods of elevated activity. A monitoring configuration that was well calibrated six months ago may be generating false signals today.
Build a quarterly review of your monitoring setup into your operational calendar. Revisit thresholds, attribution rules, and alert configurations with the same discipline you apply to the agents themselves.
Disconnecting Cost From Performance
The most complete picture of AI agent value comes from tracking cost and performance together. An agent with low costs but poor output quality is not a success. An agent with high costs delivering exceptional business value may be your most important asset. When cost monitoring and performance monitoring operate as separate systems with no connection between them, the full picture never emerges.
Connect your cost data to your performance metrics. Evaluate agents on cost-adjusted outcomes. This is what separates organizations that are managing their AI investments from those that are simply observing them.
Why This Is a Leadership Decision, Not a Technical One
It would be easy to frame AI cost monitoring as a technology problem. Build the right dashboards, configure the right alerts, and the problem is solved. That framing misses the real issue.
Cost monitoring fails in organizations not because the technical tools are unavailable, but because leadership has not made it a priority. When leadership is not actively driving AI governance, financial oversight falls into the same gap. Nobody owns it because nobody at the top has made clear that it matters.
The organizations that execute AI cost monitoring well have leaders who treat AI spending as a first-class financial category. Not a subset of IT. Not a discretionary budget that gets reviewed annually. A managed expense category with real-time visibility, clear ownership, and monthly accountability.
That posture starts at the top. If the CEO and CFO are asking for AI cost data with the same regularity they ask for revenue and operational metrics, cost monitoring gets resourced and maintained. If they are not asking, it drifts.
The Financial Layer That Separates AI Leaders From AI Experimenters
There is a meaningful difference between organizations that are experimenting with AI agents and organizations that are leading with them. The difference is not primarily about the sophistication of the agents they deploy. It is about the maturity of the operational infrastructure around those agents.
Cost monitoring is a core part of that infrastructure. It is not optional for organizations that are serious about scaling AI responsibly. Every quarter of operation without proper financial visibility is a quarter of compounding inefficiency, missed optimization opportunities, and reduced credibility with the stakeholders who control the budgets AI programs need to grow.
If your organization is working through the challenges covered in this series, from scattered knowledge bases to documentation that does not match operational reality to real-time data access gaps, Ysquare Technology works with enterprise teams to build the operational foundation that makes AI agent deployments measurable, accountable, and financially sustainable.
Follow Ysquare Technology on LinkedIn to continue following this series, or connect with our team directly to discuss where your organization stands today.
Read More

Ysquare Technology
22/06/2026

Human-in-the-Loop AI Agents: Why Enterprise Oversight Is Non-Negotiable
Here’s a question most leadership teams haven’t seriously answered yet: if your AI agent made a critical error right now, who would catch it — and how fast?
If the honest answer is “we’d probably find out eventually,” your organization has a Human-in-the-Loop (HITL) problem. And it’s one of the most expensive blind spots in enterprise AI today.
Think about this: an AI agent handling customer refunds quietly approves transactions that should have been escalated. No alert fires. No human checks in. Days pass. By the time someone notices, the same error has played out dozens of times. That’s not a technology failure — that’s a missing checkpoint.
This happens more often than people admit. The absence of human oversight in AI workflows isn’t usually a deliberate call. It’s a gradual erosion — one skipped review, one assumed safeguard, one process that “we’ll monitor later.” Leadership typically finds out only after a public incident or an operational blowup.
This post, part of our ongoing AI Agent Readiness Series, breaks down what human-in-the-loop AI actually means, what the data says about risk, and how to build real oversight into your AI agent workflows before something goes wrong.
What Human-in-the-Loop AI Actually Means (And What It Doesn’t)
Let’s be honest — “human-in-the-loop” has become one of those phrases people nod at without unpacking. So here’s what it actually means in the context of AI agents.
HITL is a deliberate system design where a real person reviews, approves, or can override an AI agent’s decision before it becomes irreversible — especially in high-stakes situations. It’s not checking a dashboard occasionally. It’s embedding human judgment at the specific points in a workflow where the cost of a wrong decision is too high to leave entirely to automation.
Without this, an agent that pulls incorrect data, sends the wrong email, or approves a flawed transaction will simply proceed. The damage happens before anyone looks at a log.
Here’s the catch: HITL isn’t a single switch you flip. It’s a series of strategic decision points woven through an agent’s workflow — from how it sources data, to what actions it’s allowed to take autonomously, to where it must stop and wait for a human call. Miss any of those points, and you’ve left a gap.
It’s closely related to the concept of an approval or review layer in AI systems, but goes further. An approval layer is procedural — it defines a step in the process. HITL is the human actually exercising judgment at that step. It also gives practical meaning to AI agent boundaries — because boundaries only work when someone is positioned to enforce them in real time.
The Real Cost of Running AI Agents Without Oversight
This isn’t a hypothetical risk. According to a 2026 study by IBM’s Institute for Business Value, conducted with Oxford Economics across 2,000 senior technology executives, organizations averaged 54 AI agent incidents in the past year that required human intervention to correct. Of those, 17% were classified as high-severity, taking over four hours to contain.
What happened during those high-severity incidents?
- 37% resulted in data exposure or security breaches
- 33% triggered cascading system failures
- 17% created compliance issues
And those are just the incidents that were documented.
The same IBM research found that two-thirds of CIOs and CTOs are now accountable for AI systems they don’t fully control. 70% said business units are deploying AI faster than IT can track. 77% reported that AI adoption is outpacing governance. Only 11% felt genuinely prepared for the scale of agent deployment coming in the next twelve months.
The real question is: what separates the organizations managing this well from those learning lessons the hard way? IBM’s analysis found that organizations embedding governance and control mechanisms directly into their AI systems experienced 25% fewer incidents than those relying on manual oversight after the fact. That gap tells you everything.
This connects directly to a broader vulnerability: security frameworks built only for human users. Traditional security assumes a person is behind every action. When an AI agent operates autonomously, that assumption breaks down — and HITL mechanisms are what re-establish meaningful control.
AI Leaders vs. Laggards: The Oversight Divide
McKinsey’s 2025 State of AI report, drawn from nearly 2,000 respondents across approximately 105 countries, found that 51% of organizations experienced at least one negative consequence from AI in the past year. Inaccuracy was the most common culprit, affecting 30% of respondents.
What most people miss in that stat is what it implies at scale. An error rate that seems manageable in a ten-transaction-a-day pilot becomes a genuine liability when the same agent processes tens of thousands. Inaccuracy doesn’t stay small — it scales with the agent.
Here’s the data point that matters most: high-performing organizations were significantly more likely to have defined HITL validation processes — 65% of them had one, compared to just 23% of other organizations. That’s not a minor gap. That’s the structural difference between companies that can safely scale AI and those that end up scaling their mistakes.
Part of why errors spread unchecked relates to data integrity. As explored in our coverage of multiple versions of truth in AI systems and the breakdown of conflicting data, a human reviewer is often the only barrier between a minor data conflict and a decision that affects a real customer. Without clear metrics for AI performance, most organizations won’t even know how often this is happening until a complaint or audit surfaces it.
Why Agentic AI Projects Collapse Without Human Checkpoints
Gartner’s June 2025 forecast delivers a blunt warning: more than 40% of agentic AI projects are predicted to be cancelled by the end of 2027. The primary reasons cited — escalating costs, unclear business value, and inadequate risk controls — aren’t technical failures. They’re governance failures.
Here’s how it typically plays out. Leadership approves an agentic AI budget based on promised efficiency gains. The agent goes live. Oversight is minimal. Errors accumulate quietly. Then the cost of correcting those errors starts appearing on the balance sheet — and suddenly the CFO is asking whether this was worth it. The project gets cancelled. Not because AI failed, but because the governance around it did.
Two factors consistently drive this pattern. First, when leadership isn’t actively engaged with AI adoption, the conversation about where human checkpoints should sit never gets escalated beyond the project team. Executives don’t know what to ask about, so they don’t ask.
Second, when there’s no clear ownership of AI systems, no one is accountable for monitoring performance. Oversight becomes everyone’s responsibility in theory and no one’s responsibility in practice.
Where Human-in-the-Loop Oversight Matters Most
Not every AI task needs constant human scrutiny. A tool that summarizes internal notes operates very differently from one that approves a loan or updates a patient record. The real expertise is knowing precisely where to draw that line.
KPMG’s Q4 AI Pulse Survey found that over 60% of enterprise leaders use HITL controls across high-risk workflows. The same survey found that 60% restrict AI agent access to sensitive data without human oversight — which also tells you that a meaningful portion still don’t have these basic safeguards in place.
Speed compounds the risk. As covered in our post on why AI agents fail without real-time data access and its companion LinkedIn piece, agents operating on live data streams make decisions at a pace no human can match in real time. That speed is the point — it’s why you’re using AI. But it’s also exactly why a clearly defined human checkpoint becomes more important, not less.
There’s also a documentation problem. If your operational workflows exist only in people’s heads and aren’t formally documented, you can’t confidently place a human review point in them. You can’t put a checkpoint on a process that’s never been written down.
The Silent Problem: When Human Reviewers Don’t Have Full Context
There’s a factor that quietly undermines HITL before it even has a chance to work: scattered knowledge.
As explored in our post on scattered knowledge sabotaging AI agent readiness and the related LinkedIn article, when critical information is fragmented across disconnected systems, the human reviewer is often working with less context than the AI agent itself has. They’re approving decisions they don’t fully understand — which makes the entire oversight process theatre, not safety.
Outdated documentation makes this worse. A reviewer trained on old process guides will confidently approve the wrong thing. As covered in our analysis of what happens when documentation lies to your AI agents, the HITL system is only as good as the information the human reviewer brings to it. If that information is stale or incomplete, oversight fails even when the process looks correct on paper.
How to Build Real Human-in-the-Loop Checkpoints (Without Slowing Everything Down)
Effective HITL doesn’t mean adding a human approval to every single AI action — that would defeat the purpose of automation entirely. The goal is strategic placement: putting human judgment exactly where the cost of error is too high to leave unreviewed.
Step 1: Map the full decision path for each agent
Don’t just document what the agent is supposed to do — document every action it’s technically capable of taking. Then categorize those actions by consequence. Sending a status update is low-risk. Issuing a refund, changing account permissions, or modifying patient records is not. High-consequence actions need human sign-off before execution, not after.
Step 2: Assign a named owner to each checkpoint
Not a team. Not a department. A specific person. If something goes wrong, there needs to be one name attached to the responsibility of that review. Vague accountability is no accountability — and that’s exactly the kind of gap that lets errors accumulate quietly.
Step 3: Track intervention frequency and reasons
If your human reviewers are overriding AI decisions 10% of the time on a specific task, that’s a signal — not just a checkpoint catching errors. It means something upstream is wrong: data quality, agent training, or workflow design. HITL data should feed back into continuous improvement, not just incident response.
The Bottom Line: Human Oversight Is What Separates Safe AI Scale from Costly Failure
Removing human oversight from AI decisions doesn’t make your organization faster. It makes it blind.
The data is consistent: organizations with embedded governance and control mechanisms report significantly fewer AI agent incidents. And analyst research links weak risk controls directly to the cancellation of AI projects that showed genuine promise.
The real question isn’t whether to include human oversight. It’s where — and that decision needs to be made before deployment, not after the first significant incident. This is a leadership call, not an engineering afterthought. It’s one of the clearest dividing lines between organizations that scale AI safely and those that end up explaining a very public mistake.
If your organization is still working out where those checkpoints should sit, that conversation is long overdue.
Read More
Ysquare Technology
19/06/2026

No Defined Boundaries for AI Agents: Why Enterprise AI Deployments Fail
Your AI agent just sent 4,000 emails to the wrong list. It updated every record in your CRM with incorrect pricing. It deleted a folder your legal team needed for an audit.
None of that happened because the AI malfunctioned.
It happened because nobody told the AI what it was not allowed to do.
This is sign number 13 of the 15 signs your organization is not ready for AI agents: no defined boundaries. And if you are a CEO, CTO, or senior leader evaluating AI deployment right now, this one deserves more attention than almost anything else on that list.
Unrestricted AI agents are not just a technical risk. They are a governance risk, a compliance risk, and a business continuity risk.
When an autonomous system can act without limits, every mistake it makes scales instantly across your entire operation.
Here is the thing most vendors will not tell you: the most dangerous thing about a powerful AI agent is not that it will fail to perform. It is that it will perform extremely well, in completely the wrong direction.
What “No Defined Boundaries” Actually Means in an AI Agent Context
When we say an AI agent has no defined boundaries, we are not talking about the agent going rogue in some science fiction sense.
We are talking about something far more common and far more damaging: an agent that has been given a goal without being given the guardrails that define how far it can go to achieve that goal.
Think of it this way. You hire a new employee and tell them to “improve customer response times.” Without further instruction, they might reasonably decide to disable the approval layer on all outbound communications, auto-close support tickets after 10 minutes, and send bulk updates to every customer who has an open case.
Technically, response times improved.
Practically, your customer trust just collapsed.
AI agents operate on the same logic. They optimize for the objective they have been given. If you have not told the agent what it cannot do, it will find the most efficient path to its goal, and that path may cross every boundary your business depends on.
AI agent scope limits are not a feature you add later. They are a foundational requirement.
Without them, you do not have an AI agent. You have a liability engine running at machine speed.
Here is what undefined boundaries look like in practice:
- An agent with access to your email system sends automated responses to clients without a review step.
- An agent managing inventory places purchase orders beyond budget thresholds because no spending cap was defined.
- An agent analyzing HR data accesses employee records outside its designated scope because nobody restricted which data sets it could query.
These scenarios are not far from reality. They are the predictable outcome of deploying AI agents without establishing what they are and are not allowed to do.
Why Leaders Underestimate This Risk Until It Is Too Late
Here is the pattern we see repeatedly with enterprise AI deployments: leadership approves the use case, the technical team deploys the agent, and the boundary question gets deferred to a later phase.
That later phase often never comes.
Part of the reason is how AI agents are sold and marketed. The emphasis is always on capability: what the agent can do, how fast it can act, how much it can automate.
The conversation about what the agent should never do gets far less attention.
The other reason is that the risk is invisible until it becomes a crisis. An agent operating without defined limits will often perform well in early testing, precisely because early testing environments are controlled.
The moment you scale to production, with real data, real customers, and real stakes, the absence of boundaries becomes catastrophic.
We have covered the downstream effects of poor governance in our earlier posts on no clear AI ownership in organizations and no metrics for AI performance. Undefined boundaries are what make both of those problems impossible to fix after the fact.
Leadership teams tend to think of AI risk in terms of the AI failing to deliver results.
The more sophisticated and more urgent risk is the AI delivering results that were never authorized.
AI agent governance cannot be an afterthought. It has to be the first conversation, not the last.
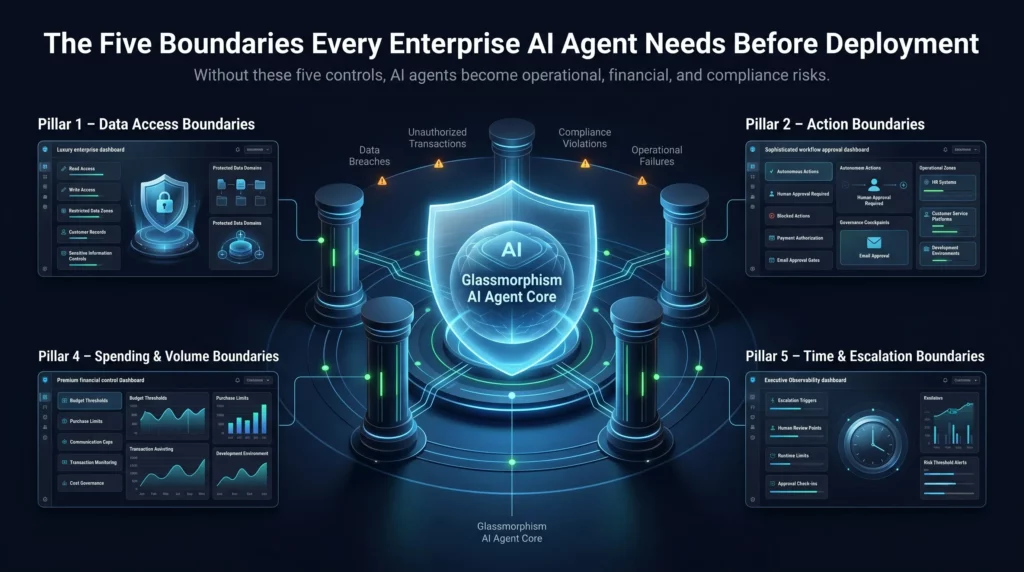
The Five Boundaries Every Enterprise AI Agent Needs Before Deployment
If your organization is deploying or evaluating AI agents, these are the five boundary categories your governance framework must address before a single agent goes live.
1. Data Access Boundaries
The first question to answer is: what data can the agent read, what can it write, and what is completely off limits?
An agent with read access to customer records should not have write access unless that specific action is part of its authorized function.
Data access boundaries prevent agents from inadvertently exposing, corrupting, or leaking sensitive information.
We have written in detail about how poor data quality undermines AI agent performance, but even clean data becomes a liability when accessed by an agent without scope restrictions.
2. Action Boundaries
Not every action an agent can perform should be performed autonomously.
Some tasks need human approval before execution. An agent that can send emails, initiate payments, update records, and trigger workflows needs clear action tiers.
Some actions can be fully autonomous. Others must trigger a review, and some should be permanently blocked.
This connects directly to the approval and review layer your AI deployment needs. Without action boundaries, there is nothing for that review layer to enforce.
3. Scope Boundaries
Scope boundaries answer a simple but critical question: where does this agent belong, and where does it not?
An HR agent should not have the ability to reach into financial systems. Likewise, a customer service agent should not have access to internal development environments.
Scope boundaries define the operational territory the agent is allowed to occupy.
4. Spending and Volume Boundaries
If the agent can trigger transactions, orders, or communications at scale, what are the caps?
A purchasing agent without spending limits can drain a budget in hours. A marketing agent without volume caps can trigger spam filters, damage email deliverability, or violate communications regulations.
5. Time and Escalation Boundaries
When should the agent stop and wait for a human?
How long should it operate autonomously before requiring a check-in? What triggers escalation?
Time boundaries prevent agents from compounding errors over extended periods before anyone notices something has gone wrong.
Unrestricted AI Actions and the Compliance Exposure Most Leaders Miss
There is a regulatory dimension to undefined AI agent boundaries that deserves direct attention, especially for organizations in healthcare, financial services, and any sector handling personal data.
When an AI agent takes an action that violates a data handling requirement, the organization is still responsible.
This includes actions such as accessing records it should not access, sending communications that breach consent rules, or retaining data beyond permitted periods.
Regulators are unlikely to accept “the AI acted on its own” as a sufficient explanation. Autonomous systems that operate under your organizational umbrella are still part of your operational responsibility.
If those systems did not have defined boundaries, that gap in governance can create serious audit, legal, and reputational exposure.
Security built only for humans is a related problem we have covered in depth. Traditional access controls assume a human is making decisions.
AI agents act at a speed and scale that completely outpaces human-designed security models. Boundary definitions are how you extend governance to autonomous behavior.
In sectors like healthcare and pharma, where we work extensively at Ysquare Technology, this compliance exposure is not theoretical. It is the difference between a successful deployment and a regulatory investigation.
How Undefined Boundaries Connect to the Other 14 Readiness Gaps
No defined boundaries does not exist in isolation. It is the consequence and the amplifier of several other readiness gaps your organization may already be experiencing.
If your knowledge is scattered across multiple tools and teams, as we covered in our post on scattered knowledge silently sabotaging AI agents, an agent without boundaries will query all of it, including the parts it should never touch.
The same challenge applies to documentation that does not match reality: if the agent is navigating processes that exist only in people’s heads, it has no map and no limits.
When there are multiple versions of truth in your data environment, an agent without scope restrictions will pull from all of them and produce outputs that are confidently wrong.
When real-time data access is missing, an agent trying to make decisions without boundaries compounds outdated information into operational errors.
Leadership not driving AI adoption is also directly connected here.
Boundary setting is a leadership decision, not a technical one. It requires executives to define what the organization is and is not willing to authorize AI to do.
When leaders are not actively involved in AI governance, boundary definitions get left to whoever deployed the agent, and they rarely have the authority or context to make those calls correctly.
The Pulse articles we have published on real-time data access, documentation failures, and scattered knowledge each point to the same underlying gap: organizations are deploying AI capability without deploying the governance that makes that capability safe.
Undefined boundaries are what happens when you stack all of those gaps together and hand the result a set of automation tools.
What Responsible AI Agent Deployment Actually Looks Like
The good news is that defining AI agent boundaries is not technically complex.
The challenge is organizational.
It requires the right people to be in the room, asking the right questions, before deployment begins.
Here is the practical framework we recommend:
1. Start with an authorization matrix.
For every function the agent will perform, define whether it is fully autonomous, requires notification, or requires approval. Build this matrix with input from legal, compliance, operations, and the technical team, not just the team deploying the agent.
2. Define exclusions explicitly.
Most governance frameworks focus on what the agent should do. Equally important is a written list of what it must never do. These exclusions should be documented, version-controlled, and reviewed regularly.
3. Build in hard limits at the system level.
Do not rely on prompt instructions alone to enforce boundaries. Hard technical limits, including spending caps, volume restrictions, and data access controls, should be enforced at the infrastructure level, not the instruction level.
4. Test for boundary violations before launch.
Before any agent goes live, run scenarios specifically designed to push the agent toward its limits. See what it does when it reaches a boundary. See what it does when someone tries to instruct it to cross one.
5. Assign ownership of the boundary framework.
Someone specific, a role not a committee, needs to be accountable for maintaining and updating the boundary definitions as the agent’s scope evolves. This connects directly to the no clear AI ownership problem we have documented across enterprise deployments.
The Real Question Every CEO and CTO Should Be Asking
Here is the real question most enterprise AI evaluations skip entirely:
“What is the worst thing our AI agent could do if it performed exactly as designed but in the wrong context?”
If you cannot answer that question, you are not ready to deploy.
The ability to define boundaries is not a sign of distrust in AI technology. It is the mark of organizational maturity.
The companies that get the most from AI agents are not the ones that gave those agents the most freedom. They are the ones that built the clearest operational contracts, defining what the agent is responsible for and what it is explicitly not.
AI agents are not magic. They are powerful tools operating within an organizational system.
Every powerful tool needs defined operating parameters.
A scalpel is extraordinary in a surgeon’s hand and dangerous without one. An AI agent without boundaries is no different.
The organizations we see deploying AI successfully, in healthcare systems, enterprise software, and large-scale operations, all share one thing: they treated boundary definition as a first-order requirement, not an afterthought.
They answered the hard governance questions before they wrote a single line of deployment code.
That is the bar your AI agent readiness framework needs to clear.
Conclusion
No defined boundaries for AI agents is not a technical problem with a technical solution.
It is a governance problem that requires organizational leadership to solve.
If you are assessing your organization’s readiness to deploy AI agents, boundary definition should be one of the first items on your evaluation checklist.
Not because you distrust the technology, but because the technology will do exactly what it is capable of doing. Without limits, that capability can eventually create consequences your business cannot absorb.
The 15 signs of AI agent unreadiness are not independent problems. They reinforce each other.
But no defined boundaries is the one that turns all the others into active risks.
Fix this one, and you make every other gap manageable. Leave it unaddressed, and every other AI investment you make becomes harder to protect.
At Ysquare Technology, we work with healthcare organizations, enterprise technology companies, and operations-driven businesses to build AI agent governance frameworks that are practical, auditable, and built to scale.
If your organization is preparing to deploy AI agents, Ysquare Technology can help you define practical governance boundaries, approval workflows, secure access controls, and scalable operating models before deployment.
Read More
Ysquare Technology
15/06/2026







