
Self-Referential Hallucination: Why AI Lies About Itself & 3 Critical Fixes

Here’s something nobody tells you when you deploy your first AI assistant: it will confidently lie to your users — not about the outside world, but about itself.
It sounds something like this:
“Sure, I can access your local files.” “Of course — I remember what you told me last week.” “My calendar integration is active. Let me book that for you right now.”
None of those statements are true. However, your AI said them anyway — with complete confidence, zero hesitation, and a tone so natural that most users just believed it.
That’s self-referential hallucination in AI. And if you’re running any kind of AI-powered product, workflow, or customer experience, this is a problem you cannot afford to ignore.
What Is Self-Referential Hallucination in AI? (And Why It’s Different From Regular Hallucination)

Most people have heard about AI hallucination by now — the model invents a fake statistic, cites a paper that doesn’t exist, or describes an event that never happened. That’s bad. But self-referential hallucination is a different beast entirely.
In self-referential hallucination, the model doesn’t make false claims about the world. Instead, it makes false claims about itself — about what it can do, what it remembers, what it has access to, and what its own limitations are.
Think about what that means for your business.
For example, a customer asks your AI support agent: “Can you pull up my previous order?” The agent says yes, starts describing what it’s doing, and then either returns garbage data or quietly stalls. Not because the integration failed — but because the model invented the capability in the first place.
Or consider a user of your internal AI tool asking: “Do you remember what project scope we agreed on in our last conversation?” The model says yes, then constructs a plausible-sounding but completely fabricated summary of a conversation that, technically, it never had access to.
In both cases, the model has no stable, grounded understanding of its own capabilities. When asked — directly or indirectly — what it can do, it fills the gap with the most plausible-sounding answer. Which is often wrong.
And here’s the catch: it doesn’t feel like a lie. It feels like a confident colleague giving you a straight answer. That’s precisely what makes it so dangerous.
Why Does Self-Referential Hallucination in AI Happen? The Architecture Problem Nobody Wants to Talk About
To fix self-referential hallucination, you first need to understand why it exists at all.
The Training Data Problem
Language models are trained to be helpful. That’s not a flaw — it’s the design goal. However, “helpful” gets interpreted in a very specific way during training: generate a response that satisfies the user’s intent. The problem is that satisfying someone’s intent and accurately representing your own capabilities are two very different things.
When a model is asked “Can you access the internet?”, it doesn’t run an internal diagnostic. Rather than checking its actual configuration, it predicts the most statistically likely next token given everything it knows — including all the AI marketing copy, product documentation, and capability discussions it was trained on.
And what does most of that training data say? That AI assistants are capable, helpful, and connected. So the model responds accordingly.
There’s no internal “self-knowledge” module — no hardcoded map of what it can and cannot do. As a result, the model guesses, just like it guesses everything else.
Why Deployment Context Makes It Worse
This problem is further compounded by the fact that many AI deployments do give models different capabilities. Some instances have web search. Others have persistent memory. Several are connected to CRMs and calendars. The model has likely seen examples of all of these during training. When it can’t distinguish which version of itself is deployed right now, it defaults to an average — which is usually wrong in both directions.
This is directly related to what we explored in The Confident Liar in Your Tech Stack: Unpacking and Fixing AI Factual Hallucinations — the same mechanism that causes factual hallucination also causes self-referential hallucination. The model fills gaps in its knowledge with confident guesses. And when the gap is about itself, the consequences are often more immediate and user-visible.
The Real-World Cost of AI Self-Referential Hallucination in Enterprise Deployments
Let’s stop being abstract for a moment.
If you’re a CTO or product leader deploying AI at scale, self-referential hallucination creates three distinct categories of damage:
1. Trust erosion — the slow kind The first time a user catches your AI claiming it can do something it can’t, they note it mentally. By the third time, they’re telling a colleague. After the fifth incident, your “AI-powered” product has a reputation for being unreliable. This kind of trust damage doesn’t show up in your sprint metrics. Instead, it shows up in churn six months later.
2. Workflow breakdowns — the expensive kind If your AI is embedded in any operational workflow — ticket routing, customer onboarding, data processing — and it consistently overstates its capabilities, the humans downstream start building compensatory workarounds. As a result, you’re now paying for AI and for the humans cleaning up after it. That’s not efficiency. That’s technical debt dressed up as innovation.
3. Compliance risk — the career-ending kind In regulated industries — healthcare, finance, legal — an AI system that makes false claims about what it can access, process, or remember isn’t just embarrassing. Moreover, it can be a direct liability issue. If your model tells a user it has stored their sensitive preferences and it hasn’t, you have a problem that no engineering patch will quietly fix.
This connects closely to a risk we unpacked in Your AI Assistant Is Now Your Most Dangerous Insider — the moment your AI starts making authoritative-sounding false statements about its own access and memory, it stops being just a UX problem. It becomes a security and governance problem.
Fix #1 — Capability Transparency: Give Your AI a Map of Itself
The most underrated fix for self-referential hallucination is also the most straightforward: tell the model exactly what it can and cannot do, in plain language, as part of its foundational context.
What Capability Transparency Actually Looks Like
In practice, capability transparency means you’re not hoping the model will figure out its own limits through inference. Instead, you’re building an explicit, structured self-description into every interaction.
Here’s what that might look like in a customer support context:
“You are an AI support agent for [Company]. You do NOT have access to user account data, order history, or billing information. You cannot book, modify, or cancel orders. You also cannot access any data from previous conversations. If users ask you to perform any of these actions, clearly and immediately tell them you do not have this capability and direct them to [specific resource or human agent].”
Simple. Blunt. Effective.
Why Listing Only Capabilities Is Not Enough
What most people miss here is that this declaration has to be exhaustive, not aspirational. Don’t just describe what the model can do — explicitly describe what it cannot do. Because the model’s bias is toward helpfulness, if you leave a capability undefined, it will assume it can probably help.
This approach also handles edge cases you might not have anticipated. For instance, what happens when a user phrases the question indirectly: “So you’d be able to pull that up for me, right?” Without a well-specified capability block, an under-specified model will often simply agree. A clear capability declaration, however, gives the model a concrete reference point to correct against.
Furthermore, the Ai Ranking team has built this kind of structured transparency directly into enterprise AI deployment frameworks — because it’s the difference between an AI that sounds capable and one that actually is. You can explore that approach at airanking.io.
Fix #2 — Controlled System Prompts: The Architecture That Actually Prevents Capability Drift
Capability transparency tells the model what it is. Controlled system prompts, on the other hand, are how you enforce it.
The Hidden Source of Capability Drift
Here’s the real question: who controls your system prompt right now?
In many organizations — especially those that have deployed AI quickly — the answer is murky. A developer wrote an initial prompt. Someone in product tweaked it. A customer success manager added a few lines. Nobody fully reviewed the final result. As a result, your AI is now operating with a system prompt that’s partially contradictory, partially outdated, and occasionally telling the model it has capabilities it definitely doesn’t have.
This is capability drift. In fact, it’s one of the most common and overlooked sources of self-referential hallucination in production deployments.
Building a Governed Prompt Pipeline
The fix is to treat your system prompt as a governed artifact, not a scratchpad. Specifically, that means:
- Version control — your system prompt lives in a repo, not in a config dashboard nobody reviews
- Mandatory capability declarations — any update to the prompt must include a review of the capability section
- Adversarial testing — you run test cases specifically designed to probe whether the model will claim capabilities it shouldn’t
This connects to something we discussed in depth in The Smart Intern Problem: Why Your AI Ignores Instructions. A poorly structured system prompt is like a job description that contradicts itself — consequently, the model defaults to its training instincts when your instructions are ambiguous. Controlled system prompts remove that ambiguity entirely.
One practical technique: build a “capability assertion test” into your QA pipeline. Before any system prompt goes to production, run it through questions specifically designed to elicit false capability claims — “Can you access my files?”, “Do you remember our last conversation?”, “Can you see my account details?” If the model says yes in a context where it shouldn’t, you have a problem in your prompt. More importantly, you catch it before users do.
The Ai Ranking platform includes built-in evaluation layers for exactly this kind of prompt governance. See how it works at airanking.io/platform.
Fix #3 — Explicit Boundaries in System Messages: Teaching Your AI to Say “I Can’t Do That”
Here’s something counterintuitive: getting an AI to confidently say “I can’t do that” is one of the hardest things to engineer.
The Problem With Leaving Refusals to Chance
The model’s training pushes it toward helpfulness. Meanwhile, the user’s expectation is that AI is capable. And the commercial pressure on AI products is to seem more powerful, not less. So when you need the model to clearly, confidently, and naturally decline a request based on a capability gap — you’re fighting against all of those forces simultaneously.
Explicit boundaries in system messages are how you win that fight.
In practice, your system prompt doesn’t just describe what the model can’t do — it also defines how the model should respond when it encounters those limits. You’re scripting the refusal, not just declaring the boundary.
For example:
“If a user asks whether you can remember previous conversations, access their personal data, or perform any action outside of [defined scope], respond this way: ‘I don’t have access to [specific capability]. For that, you’ll want to [specific next step]. What I can help you with right now is [redirect to valid capability].'”
Notice what this achieves. Rather than leaving the model to improvise a refusal, it gives the model a clear, branded, user-friendly response pattern — so the conversation continues productively instead of ending in an awkward apology.
Boundary Reinforcement in Long Conversations
There’s also a longer-term dynamic to consider. If a conversation runs long enough — especially in a multi-turn session — the model can gradually “forget” the boundaries set at the top and start reverting to default assumptions about its capabilities. This is where context drift and self-referential hallucination intersect directly. We covered how to handle that in When AI Forgets the Plot: How to Stop Context Drift Hallucinations.
The solution is boundary reinforcement — either through periodic re-injection of the capability block in long sessions, or through a retrieval mechanism that pulls the relevant constraint back into context when certain trigger phrases appear. It sounds complex; in practice, however, it’s a few dozen lines of logic that save you from an enormous amount of downstream chaos. Ai Ranking provides a full implementation guide for boundary enforcement in enterprise AI contexts at airanking.io/resources.
What Self-Referential Hallucination Tells You About Your AI Maturity
Let me be honest with you: if your AI system is regularly making false claims about its own capabilities, that’s not merely a prompt engineering problem. It’s a signal that your AI deployment is still operating at a surface level.
Most organizations go through a predictable arc. First, they deploy AI quickly — because the pressure to ship is real and the competitive anxiety is real. Then they discover that “deployed” and “reliable” are two very different things. After that reckoning, they start retrofitting governance, testing, and structure back into a system that was never designed for it from the ground up.
Self-referential hallucination is usually one of the first symptoms that triggers this reckoning. Unlike a factual hallucination buried in a long response, a capability claim is immediate and verifiable. The user knows right away when the AI claims it can do something it can’t — and so does your support team when the tickets start coming in.
The good news: it’s also one of the most fixable problems in AI deployment. Unlike hallucinations rooted in training data gaps, self-referential hallucination is almost entirely a deployment and configuration issue. You can therefore address it systematically, without waiting for model updates or retraining. Teams that fix this tend to see a noticeable uptick in user trust — and a measurable reduction in support escalations — within weeks, not quarters.
The three fixes — capability transparency, controlled system prompts, and explicit boundary messages — work together as a stack. Any one of them alone will reduce the problem. However, all three together essentially eliminate it.
The Bottom Line
Your AI doesn’t lie to be malicious. It lies because it’s trying to be helpful, and nobody gave it a clear enough picture of what “helpful” means within its actual constraints.
Self-referential hallucination is ultimately the gap between what your model was trained to do in general and what your specific deployment actually allows it to do. Close that gap — with explicit capability declarations, governed system prompts, and scripted boundary responses — and you don’t just fix a bug. You build an AI system that your users can trust on day one and every day after.
In a world where users are getting increasingly skeptical of AI-powered products, that trust is worth more than any feature on your roadmap.
Frequently Asked Questions
1. What is self-referential hallucination in AI?
Self-referential hallucination in AI occurs when a language model makes false claims about its own capabilities, memory, or access rights — for example, claiming it can remember past conversations or access local files when it cannot. Unlike factual hallucination, which involves inventing external facts, self-referential hallucination is specifically about the model misrepresenting itself.
2. How is self-referential hallucination different from regular AI hallucination?
Regular AI hallucination involves the model generating false information about the external world — fake citations, fabricated statistics, or invented events. Self-referential hallucination, however, is when the model generates false information about itself: its capabilities, its memory, and its data access. Both are harmful, but self-referential hallucination is often more immediately visible and therefore more actionable.
3. Why does my AI claim it can do things it cannot?
Because language models are trained to be helpful, and "helpful" often means giving the user the answer they expect. When a model doesn't have a clear, explicit description of its own limitations, it defaults to the most statistically likely response based on training — which often includes examples of AI assistants with broader capabilities than your specific deployment actually has.
4. Can self-referential hallucination be fixed without retraining the model?
Yes. Self-referential hallucination is primarily a deployment and configuration problem, not a training problem. As a result, the three core fixes — capability transparency, controlled system prompts, and explicit boundary scripting — can all be implemented at the application layer without touching the underlying model at all.
5. What should a system prompt include to prevent AI capability hallucination?
An effective system prompt should: (1) explicitly list what the model CAN do in this specific deployment, (2) explicitly list what it CANNOT do, (3) define how the model should respond when it encounters requests outside its capability scope, and (4) include scripted redirect responses that guide users to appropriate alternatives. In short, it should leave nothing undefined.
6. How do I test whether my AI is self-referentially hallucinating?
Run adversarial capability probe questions directly against your deployed model: "Can you access my files?", "Do you remember our last conversation?", "Can you see my account history?" If the model answers yes to capabilities it doesn't actually have, you have a self-referential hallucination problem. Moreover, this test should be part of your QA pipeline before every prompt update goes to production.
7. Is self-referential hallucination a compliance risk?
In regulated industries, yes. If an AI system falsely claims to store user preferences, retain session data, or have access to sensitive records when it doesn't — or the reverse — that misrepresentation may create direct liability under data protection regulations. Consequently, accurate capability disclosure is no longer just a UX concern; it's increasingly a legal and compliance concern.
8. What is capability transparency in AI deployment?
Capability transparency is the practice of building an explicit, structured self-description into your AI system's context — telling the model clearly and completely what it can and cannot do in a given deployment. It's the primary defense against self-referential hallucination and, furthermore, it's the foundation of reliable AI system design at any scale.
9. Does self-referential hallucination get worse in longer conversations?
Yes. In long multi-turn sessions, models are prone to "context drift" — the constraints set at the beginning of a session gradually lose influence as the conversation history fills the context window. As a result, boundary reinforcement techniques — such as periodic re-injection of capability declarations or trigger-based constraint retrieval — are specifically designed to address this degradation over time.
10. How do enterprises prevent AI from overstating its own capabilities to customers?
The most effective enterprise approach combines three layers: first, a rigorously governed system prompt with explicit capability and limitation declarations; second, scripted refusal and redirect patterns so the model knows exactly how to respond when it hits a boundary; and third, a QA pipeline that includes capability probe testing before any system prompt update reaches production.

Why Leadership Must Drive AI Agent Adoption Across the Organization
Here is a question worth sitting with: Your company just spent six figures on AI tools. Your IT team built the pilots. Your vendor gave three onboarding sessions. And yet, six months in, adoption across the organization is hovering somewhere between “low” and “invisible.”
Sound familiar?
This is not a technology problem. It is not a budget problem. And it is definitely not a problem your IT team can fix on their own.
When leadership isn’t driving AI adoption, everything else you do to push it forward is just noise. Teams take their cues from the top. If they don’t see their managers, directors, and executives actively using AI, talking about AI, and holding people accountable to AI outcomes, then AI becomes just another initiative that will quietly fade away after the next quarterly review.
The data backs this up. McKinsey’s 2025 Workplace AI report surveyed 3,613 employees and 238 C-level executives and found that employees are ready for AI, but leaders are not steering fast enough. The biggest barrier to success is leadership.
That is not a small finding. That is the finding. And if you’re a CEO, CTO, or senior business leader, this one is squarely on your desk.
Why Leadership Isn’t Driving AI Adoption Is the Real Bottleneck
Most organizations frame AI adoption as a rollout problem. They build a roadmap, pick a vendor, set up training sessions, and wait for adoption to happen. It doesn’t. Because adoption isn’t a rollout problem. It’s a culture problem, and culture is set by leaders.
Think about how any new behavior spreads inside a company. People don’t change how they work because they attended a webinar. They change because they see their peers doing things differently, because their manager asks them different questions, and because their performance is measured against different outcomes. None of that happens without leadership actively driving it.
When executives treat AI as someone else’s responsibility, a few predictable things occur. Teams see AI as optional. Middle managers don’t prioritize it. Budgets get questioned at renewal time. And the early adopters who were genuinely excited burn out trying to evangelize uphill without any support.
McKinsey’s research shows that AI high performers are three times more likely to have senior leaders who demonstrate ownership of and commitment to their AI initiatives. Those same leaders actively use AI themselves and role-model the behavior they want to see across the organization.
That three-times multiplier isn’t marginal. It’s the difference between companies that are genuinely transforming and companies that are running expensive pilots forever.
What the Numbers Actually Say About Leadership and AI Success

The statistics here are sobering, and leaders need to face them honestly.
According to McKinsey’s 2025 State of AI report, 88% of organizations reported regular AI use in at least one business function in 2025, compared with 78% a year earlier. But only about one-third have begun scaling AI programs across the organization. The gap between “we’re using AI somewhere” and “AI is changing how we operate” is enormous, and leadership behavior sits right in the middle of it.
A 2025 report from WRITER, which surveyed 1,600 knowledge workers including 800 C-suite executives, found that more than one in three executives describe their generative AI adoption as a “massive disappointment.” Two-thirds of C-suite leaders reported tension between IT teams and other business units around AI implementation.
Here’s the number that should alarm every board room: Only 28% of organizations report that their CEO takes direct responsibility for AI governance and oversight. Yet the companies where the CEO is directly involved in AI governance report meaningfully higher business impact from their AI investments.
The math is simple. When the CEO owns it, it gets resourced, prioritized, and measured. When AI is delegated to a single team, it gets stuck.
McKinsey’s March 2025 report, “How Organizations Are Rewiring to Capture Value,” reinforces this directly: only 28% of respondents whose organizations use AI say their CEO oversees AI governance, and CEO oversight is strongly correlated with higher self-reported bottom-line impact.
The IBM Watson Story: A Masterclass in What Happens Without Real Governance
No case study on AI adoption failure is more instructive than the story of IBM Watson for Oncology.
IBM positioned Watson Health as a moonshot. The technology would democratize elite oncology expertise, helping clinicians around the world make better cancer treatment decisions. IBM committed billions of dollars. The marketing was confident. The promise was enormous.
What actually happened was a governance and leadership failure at scale.
The system was developed with training data curated by a small group of physicians using hypothetical patient cases, not real clinical data. When hospitals tried to deploy it in the real world, the recommendations were often inconsistent with national treatment guidelines. One physician at a Florida hospital told IBM executives the system was “worthless” for most cases, and that the hospital had bought it largely for marketing purposes.
When MD Anderson Cancer Center, one of Watson’s most prominent partners, transitioned from its legacy EHR system to Epic Systems, Watson couldn’t access live patient data. A $62 million investment became, in the words of one review, a “custom demo.”
By 2022, IBM announced the sale of Watson Health’s healthcare data and analytics assets to Francisco Partners. Financial terms were not officially disclosed, though reports placed the deal at more than $1 billion, a figure widely understood to represent a fraction of the total capital invested in acquisitions, development, and deployment across the life of the program.
The core failure wasn’t the technology itself. As researchers and analysts have since noted, the problem was structural and organizational. IBM’s leadership scaled the product before the conditions for it to work were established. There was no rigorous governance to catch the gap between what was being promised externally and what was actually possible internally. Clinical experts weren’t embedded deeply enough. The business case was built on narrative rather than evidence.
This is precisely what happens when AI adoption is treated as a product launch rather than as an organization-wide capability change that requires sustained leadership ownership at every level.
Source: Henrico Dolfing Case Study Analysis, December 2024
What Leaders Actually Need to Do Differently
The answer to “leadership isn’t driving AI adoption” isn’t to send another memo or mandate a new tool. It is to change behavior, specifically leadership behavior, in visible and consistent ways.
Here’s what that looks like in practice.
Use the tools publicly. When a CEO shares that they used AI to prepare for a board meeting, or a VP mentions in a team call that they ran a prompt to summarize competitive research, those small moments signal that AI is real, not aspirational. Visibility matters enormously.
Ask AI-related questions in reviews. If the only metrics being reviewed are the same ones from two years ago, nothing changes. Leaders who ask “how did we use AI to get this result?” or “where did AI save us time this quarter?” are reshaping what the team pays attention to.
Assign explicit ownership. Not a committee. Not a shared responsibility. One named person whose job includes making AI adoption work, with a budget, a timeline, and reporting lines directly into leadership. As our analysis of why leadership must drive AI agent adoption shows, the moment there is no single owner, accountability evaporates.
Remove the barriers teams face. Most frontline employees aren’t anti-AI. They’re time-poor, risk-averse, and waiting for permission. Leaders need to create psychological safety around experimentation, reduce the bureaucratic friction around tool access, and make it easy to try things without fear of looking incompetent.
Tie AI outcomes to performance conversations. What gets measured gets done. When teams know that AI capability building is part of how they are evaluated, they prioritize it.
The Readiness Problem Leaders Keep Ignoring
Leadership behavior is only one part of the equation. Even the most committed executive can’t drive adoption if the organization’s infrastructure isn’t ready for AI agents to work.
This is a critical point that gets skipped in most leadership conversations about AI.
Your AI agents are only as reliable as the data and systems they operate in. If knowledge is scattered across tools and teams, agents won’t find what they need. We cover this challenge in depth in our piece on why scattered knowledge is silently sabotaging your AI, and in our blog on scattered knowledge and AI agent readiness.
If your documented processes don’t reflect how work actually happens, agents will make decisions based on outdated or wrong information. This is explored in our piece on what happens when your documentation lies, and in our undocumented workflows blog.
If different teams are working from different versions of the same data, the conflict kills AI decision quality before it even starts. Our article on multiple versions of truth and why conflicting data kills your AI makes this concrete, and our blog on multiple versions of truth walks through the fix.
If agents can’t access real-time data, every decision they make is already stale. We break this down in why real-time data access is the hidden reason your AI agents stall and in our blog on AI agents failing without real-time data access.
And if there are no approval or review layers, no metrics for performance, and security systems that were designed for humans rather than autonomous agents, you’re not just slowing adoption down. You’re creating risk. These exact gaps are covered in our deep dives on AI agents with no approval or review layer, security built only for humans, and no metrics for AI performance.
Leaders who genuinely want to drive AI adoption have to ask: are we actually ready for agents to operate here? Or are we trying to drive on a road that hasn’t been built yet?
The Leadership Gap vs. The Readiness Gap: A Practical Framework
Understanding both gaps helps you prioritize the right interventions. Here is a simple way to think about where your organization stands.
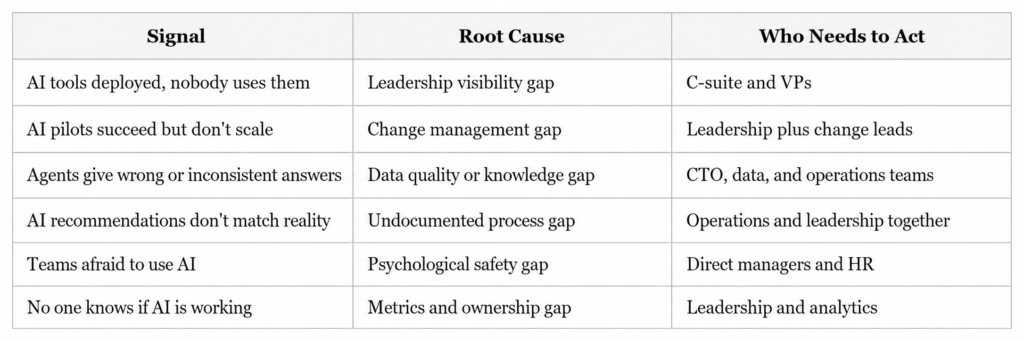
Most organizations have problems in multiple columns at once. The common thread is that none of these get fixed without leadership actively identifying the problem, naming it publicly, and committing resources to solve it.
Three Questions Every Leadership Team Should Answer This Quarter
If you’re serious about closing the gap between “we have AI” and “AI is working for us,” start with these three questions in your next leadership session.
One: Where is AI visibly showing up in our leadership behavior? Not in slides. In actual day-to-day decisions, communications, and reviews. If the honest answer is “not really anywhere,” that’s where to start.
Two: Who owns AI outcomes across this organization? Not IT. Not a vendor. A named individual with authority, accountability, and a direct line to leadership. If you can’t answer this in thirty seconds, ownership doesn’t exist.
Three: What does success look like in ninety days? Not annual ROI projections. A concrete, measurable outcome that proves the investment is moving in the right direction. If there’s no near-term success metric, there’s no accountability loop.
These aren’t complicated questions. But they require an honest conversation that many leadership teams keep avoiding because they’re busy and because the status quo feels comfortable.
The status quo, meanwhile, is getting more expensive every quarter.
What High-Performing Organizations Do Differently
McKinsey’s research identifies a consistent pattern among AI high performers. They’re not necessarily the companies with the biggest budgets or the most sophisticated technology. They’re the companies where senior leaders demonstrate visible ownership of AI initiatives, actively use AI themselves, and role-model the adoption behavior they want to see.
These organizations treat AI not as an IT capability but as a business capability. The difference in framing changes everything: who owns it, how it’s resourced, how progress is measured, and how it’s talked about internally.
They also do something that most organizations skip. They redesign workflows rather than bolting AI onto existing ones. Leaders at these companies are willing to ask harder questions about how work actually flows, where decisions get made, and what needs to change structurally for AI to deliver real value.
That kind of organizational introspection doesn’t happen at the team level. It requires leadership to drive it.
Conclusion: Adoption Starts at the Top, Not at the Tool
There’s a version of this story that ends well, and a version that doesn’t. The difference isn’t the quality of the AI tools, the size of the implementation budget, or the enthusiasm of the early adopters.
The difference is whether your leaders treat AI as someone else’s problem or as their own.
When leadership isn’t driving AI adoption, you get pilots without scale, investments without returns, and teams that quietly go back to doing things the way they always have. When leadership does drive it, you get the 3x performance multiplier McKinsey observed. You get teams that feel permission and urgency to change. You get an organization that actually transforms.
The infographic above puts it plainly: “If leaders don’t actively use AI, teams won’t prioritize it. Adoption starts at the top.” That’s not a motivational phrase. That is an operational truth backed by the data.
Your next move is not another pilot. It’s a leadership conversation about ownership, visibility, and accountability. Start there, and everything else becomes easier.
Ready to Assess Your AI Agent Readiness?
At Ysquare Technology, we help enterprise and growth-stage companies identify exactly where their AI adoption is breaking down and what leadership, data, and infrastructure changes are needed to fix it.
If your AI investments aren’t delivering what you expected, the problem is almost certainly upstream of the technology. Let’s find it together.
Connect with us on LinkedIn or visit www.ysquaretechnology.com to start the conversation.
Read More

Ysquare Technology
01/06/2026

AI Performance Metrics: Why Your AI Is Losing Money
Most leaders think deploying AI is the hard part. It is not. Running AI without any way to measure whether it is actually working, that is the hard part. And right now, a startling number of organizations are doing exactly that.
Here is what most people miss: deploying an AI agent without performance metrics is not neutral. It is a slow bleed. Every day the system runs without measurement, errors go undetected, costs drift upward, and the gap between what you expected and what you are getting quietly widens. By the time someone notices, the damage is already embedded in your operations.
This article is for CEOs, CTOs, and technology leaders who are serious about getting real business value from AI, not just deploying it and hoping for the best. If your AI agents are live but you cannot answer the question “Is this working and how do we know?”, keep reading. We are going to change that.
Why “No Metrics for AI Performance” Is Sign Number Eight on the AI Readiness Watchlist
When we talk about the 15 signs your organization is not ready for AI agents, the absence of AI performance metrics sits at number eight for a reason. It sits squarely in the middle because it is the hinge. Everything before it, from scattered knowledge and undocumented workflows to poor data quality and no approval layers, creates conditions where AI fails. But without measurement, you never know which of those failures is happening, or how badly.
The phrase “what gets measured gets optimized” sounds like a motivational poster. In AI operations, however, it is a survival principle. Without a measurement layer, your AI agent has no feedback mechanism. It cannot improve because nothing tells it, or you, when it is wrong. Mistakes that a human reviewer would catch in a traditional workflow scale silently through automated systems until they surface as a business problem rather than an AI problem.
This is the real danger. Not that your AI will fail dramatically on day one. But that it will fail quietly, incrementally, across thousands of interactions, and you will have no idea until the downstream consequences surface in your P&L, your customer satisfaction scores, or your compliance audit.
What the Data Actually Says About AI Measurement
The numbers here are genuinely alarming. Moreover, they deserve to be seen clearly rather than buried in footnotes.
McKinsey’s research confirms that fewer than 20% of organizations track well-defined KPIs for their GenAI solutions. That means more than four out of five organizations are running AI without a structured measurement framework. According to the same research, scaling AI without defined metrics is consistently cited as the primary reason AI programs stall out before they deliver value.
Gartner’s AI Maturity Survey found that only 63% of high-maturity organizations, the ones already considered advanced in AI adoption, run financial risk analysis, ROI analysis, and measure customer impact in any structured way. Think about what that means for organizations still in earlier stages of the journey.
Deloitte’s State of GenAI 2024 report found that 41% of business leaders openly admit they struggle to measure AI’s impact on their operations. IBM’s ROI of AI Report, conducted by Morning Consult, put the positive ROI figure at just 47%. More than half of companies investing in AI cannot confirm they are seeing returns.
McKinsey’s Superagency in the Workplace report found that 92% of companies plan to increase their AI investments over the next three years, while only 1% of leaders describe their companies as mature in AI deployment. The message is clear: AI investment is accelerating, but AI operating maturity is still far behind.
This is not an AI problem. It is a management problem. And it is one that can be fixed.
What “No AI Performance Metrics” Actually Looks Like Inside an Organization
It rarely looks like chaos. That is part of what makes it so hard to catch. Here is what it actually looks like day to day.
Your dashboards show activity, not outcomes. You can see how many tasks the AI agent processed, how many queries it responded to, how many workflows it touched. What the dashboard does not show is whether any of that activity produced a better result than what you had before. Volume is not value.
Improvement happens by accident when it happens at all. Without baselines and benchmarks, you have no way to distinguish a genuine performance gain from random variance. Your AI might get better over time, or it might quietly degrade. You will have no way to tell the difference until something breaks loudly enough to notice.
The AI team and the business team are measuring different things. Engineers track uptime, latency, and model accuracy. Business leaders track revenue, customer satisfaction, and operational costs. With no shared measurement framework, these two groups are essentially working on different problems and calling them the same project.
Errors compound before anyone catches them. This connects directly to the risk of running AI without an approval or review layer in your workflows. If you want to understand how unreviewed AI outputs scale into operational risk, the breakdown of what happens when no approval or review layer exists in your AI setup makes the connection concrete. Without metrics, you cannot see errors accumulating. Without a review layer, you cannot stop them from spreading.
The IBM and MD Anderson Case Study: A Sixty-Two-Million-Dollar Lesson in Missing Metrics
When people ask for a real-world example of what it costs to run AI without a clear measurement and validation framework, this is the one that belongs in every boardroom conversation.
IBM and MD Anderson Cancer Center partnered to build the Oncology Expert Advisor, a Watson-powered advisory tool designed to assist oncologists in clinical decision-making. The project was well-funded, medically ambitious, and backed by genuine intent to improve patient care. A prototype was tested in the leukemia department.
MD Anderson cancelled the project in 2016 after spending approximately sixty-two million dollars. As reported by IEEE Spectrum, the system never became a commercial product. The project ran into serious difficulties with the realities of clinical data, including the complexity of electronic health records, validation challenges, and the absence of clear performance checkpoints that would have allowed teams to catch integration problems early and course-correct before costs escalated.
The lesson is not that AI cannot work in healthcare. It absolutely can, and does. The lesson is that high-stakes AI needs clear success criteria, clinical validation standards, integration readiness checks, and measurable performance milestones before it moves toward production deployment. Without those checkpoints built in from the start, you have no mechanism to identify failure until the budget is already spent.
Source: IEEE Spectrum, “IBM Watson, Heal Thyself: How IBM Overpromised and Underdelivered on AI Health Care.”
The AI Performance Metrics That Actually Move the Needle
Here is where most measurement frameworks go wrong. They measure what is easy to pull from a system log rather than what tells you whether the AI is creating business value. Let us fix that.
Accuracy and Quality Metrics
First, you need to know whether the AI is producing correct, useful outputs. The most practical ones to track are task completion rate (did the agent finish what it was asked to do), recommendation acceptance rate (when the AI suggests something, how often do humans agree it was right), and error rate per thousand interactions. Furthermore, if your AI is producing outputs that humans routinely override or correct, that pattern is itself a critical data point.
Efficiency Metrics
Beyond accuracy, efficiency metrics connect AI activity directly to cost and speed. Compare average handling time before and after AI deployment on the same process. Track cost per task completed. Measure the ratio of AI-resolved interactions to human-escalated ones. As a result, you will know quickly whether the AI is automating volume while also increasing cost per unit, which happens more often than most leaders expect.
Business Impact Metrics
These are, ultimately, the ones that justify the budget conversation. How much revenue has AI-assisted decisions influenced? What has happened to customer satisfaction scores in workflows the AI now touches? Are operational costs in targeted areas trending down or up? In short, these metrics transform AI from an IT project into a business strategy.
Risk and Safety Metrics
Finally, risk and safety metrics are consistently the most overlooked category. Track the rate at which AI-generated outputs require human correction after the fact. Monitor escalation volumes for signals that the AI receives requests outside its reliable range. Run regular compliance checks on AI-involved decisions. These metrics are your early warning system, and without them, you are operating blind.
If your data quality is inconsistent across systems, all of these metrics will be unreliable at the source. This is why addressing multiple versions of truth in your data is not a separate workstream from building an AI measurement framework. They are the same problem looked at from two angles.
Why Most AI Measurement Frameworks Fail Before They Start

Here is the catch that most implementation guides skip over. Building a metrics framework after deployment is significantly harder than building it before. And most organizations try to do exactly that.
By the time you realize you need measurement, your AI has already been running for weeks or months. You have no baseline to compare against. The teams closest to the pre-AI process have moved on to other priorities. Moreover, real-world inputs have already shaped the AI’s behavior in ways that teams never benchmarked, so there is nothing meaningful to measure improvement against.
This is why the measurement conversation needs to happen before go-live, not after. When you design the AI agent’s workflow, that is when you define success. What does this agent need to accomplish for this deployment to be worthwhile? Write it down in specific, measurable terms. That sentence becomes your first performance metric.
The other failure pattern is assigning measurement responsibility to nobody in particular. Metrics without owners are decoration. Someone on your team needs to own each KPI, report on it regularly, and have the authority to escalate when it moves in the wrong direction. If measurement is everyone’s responsibility, it will quickly become no one’s.
This connects to a broader readiness challenge around ownership in AI programs. The same dynamic that creates problems when no one owns AI outcomes at the strategic level plays out identically at the metrics level. Accountability has to be assigned, not assumed.
How to Build a Practical AI Performance Measurement Framework in Four Steps
You do not need a six-month consulting engagement to get started. Here is a practical sequence that works.
Step one: Define success before deployment. For each AI agent or workflow, write one to three specific statements that describe what success looks like. Keep them concrete. For instance, “The AI will resolve 65% of Tier 1 support queries without human escalation” is a success statement. “The AI will help improve customer service” is not.
Step two: Establish your baseline. Pull the current performance data for the process your AI is replacing or augmenting. How long does it take? How accurate is it? What does it cost? How satisfied are customers with the outcome? That data is your starting point for every future comparison.
Step three: Build measurement into the rollout schedule. Do not treat monitoring as an afterthought. Therefore, schedule weekly check-ins in the first month, moving to monthly reviews as performance stabilizes. Make AI performance a standing agenda item in your technology and operations reviews.
Step four: Assign ownership and act on the data. Every metric needs a named owner. Every review needs to end with a decision, whether to stay the course, adjust the AI’s configuration, escalate a data quality issue, or retrain on new inputs. Consequently, measurement only creates value when it drives action.
If you are finding that your AI agents struggle because of data fragmented across systems, the underlying problem of scattered knowledge silently sabotaging your AI is worth addressing alongside your measurement buildout. Metrics built on fragmented data will give you fragmented insights.
The Leadership Reality Check
Let us be honest about something. Metrics programs do not fail because the metrics are wrong. They fail because leadership does not review them consistently enough to create accountability.
Gartner’s research found that only 27% of executives have a comprehensive AI strategy, and just 20% believe their workforce is actually ready for AI at scale. As a result, that gap in strategic preparedness shows up most visibly in measurement. When leadership is not looking at AI performance data, no one below them will treat it as a priority either.
If you are a CTO or CIO reading this, the most direct thing you can do to accelerate your AI measurement maturity is put AI performance metrics in your regular business reviews. Not as a technology report. As a business report. Accuracy rates, cost per task, escalation volumes, and business outcome trends sitting in the same review as revenue and customer satisfaction. That framing changes how every team in the building thinks about AI accountability.
In addition, if your AI agents operate without real-time data, the measurement challenge becomes even harder because your AI outputs outdated information before it ever reaches a decision-maker. The full picture of why AI agents fail without real-time data access is a related read that fills in this gap.
From Measurement to Continuous Improvement
The point of tracking AI performance metrics is not to generate reports. It is to create a closed loop where your AI system gets progressively better over time.
High-maturity AI organizations understand this well. Gartner’s research found that 45% of organizations with strong AI maturity keep their AI initiatives in production for three or more years, against just 20% of low-maturity organizations. The difference is almost never the sophistication of the initial model. Instead, it is whether the organization has the measurement and iteration infrastructure to keep improving after launch.
The loop looks like this: deploy with defined success criteria, measure against them, identify the gap between actual and target performance, adjust, and measure again. That cycle, repeated consistently, is what separates AI programs that deliver compounding value from those stuck permanently in pilot phase.
Without performance data, however, this loop cannot close. You cannot adjust what you cannot see. And if your documentation of how those workflows are supposed to run does not match how they actually run, your measurement baseline rests on false assumptions. The full picture of what happens when your documentation lies about how work actually gets done explains why this matters before you build any measurement framework.
The Connection Between Measurement and Every Other AI Readiness Challenge
Here is what most people miss when they think about AI performance metrics as a standalone issue. Measurement does not fix your AI readiness gaps in isolation. Rather, it makes every other gap visible.
Poor data quality shows up immediately in your accuracy metrics. They will start reflecting noise before you even realize the source of the problem. Beyond accuracy, if your AI agents are relying on conflicting data across multiple systems, inconsistent outputs will show up in your error rates as well. Processes buried in people’s heads rather than documented anywhere cause your AI’s task completion rate to plateau at a frustratingly low ceiling. Similarly, a security model built only for human users and not for autonomous agents will cause your risk metrics to flash warnings before your security team even identifies the source.
This is why measurement is the pivot point in the AI readiness journey. Not because it solves everything, but because it makes everything else solvable. You cannot fix what you cannot see. And right now, most organizations cannot see nearly enough.
The connection between real-time data access and measurement accuracy is also worth calling out explicitly. If your AI agents are acting on data that is hours or days out of date, the actions they take will look correct in the moment and incorrect in the outcome. Understanding why real-time data access is the hidden reason AI agents struggle will save you from building measurement frameworks on top of a stale data problem.
And if your workflows are undocumented and buried inside individual employees, your AI agent will hit invisible walls that your metrics will expose but that your team will struggle to diagnose without better process documentation.
Conclusion: The AI You Cannot Measure Is the AI You Cannot Trust
Here is the real shift in thinking we want to leave you with. Measurement is not a reporting function. It is a trust function.
You cannot trust an AI system you cannot measure. You cannot justify continued investment in something you cannot prove is working. And you cannot build organizational confidence in AI adoption when the people closest to the work have no visibility into whether the AI is helping or hurting.
The good news is that this is one of the most actionable AI readiness gaps on the list. You do not need a perfect framework on day one. You need clear success criteria, an honest baseline, a consistent review cadence, and named owners for each metric. Start there, and build from it.
At Ysquare Technology, we help organizations design and deploy AI agents with the measurement infrastructure built in from the start, not bolted on after the problems show up. If your AI is running without metrics, or your metrics are tracking the wrong things, we can help you build a framework that connects your AI performance directly to business outcomes.
Connect with us on Ysquare Technology’s LinkedIn page or visit ysquaretechnology.com to start the conversation. Your AI is either getting better every week or quietly drifting. Measurement is how you make sure you know which one is happening.
Read More
Ysquare Technology
25/05/2026

Why Security Built Only for Humans Will Break Your AI Agent Strategy
Your firewall works. Your access controls look clean. Your IT team passed the last compliance audit without a single flag. So why does your AI agent keep doing things it was never supposed to do?
Here’s the catch. Most enterprise security models were designed with one assumption at the center: a human is always in the loop. Someone logs in. Another person requests access. A manager approves a transaction. Every control, every audit trail, and every permission layer centers on the idea that a person is making the decision.
AI agents do not work that way.
When you introduce autonomous AI agents into your workflows, you are not just adding a new tool. You are introducing a new type of actor into your systems — one that operates continuously, makes decisions at machine speed, and does not wait for someone to click “approve.” If your security model has not kept up, you are running a powerful autonomous system through a framework that was never built to contain it.
This is one of the most overlooked risks in enterprise AI adoption today. And it is silently growing in organizations that believe they are ready for AI agents when, in reality, they are only ready for AI tools that humans control.
What “Security Built Only for Humans” Actually Means

Traditional enterprise security is built on a few foundational ideas. Role-based access control (RBAC) gives specific users specific permissions. Multi-factor authentication (MFA) verifies identity at login. Audit logs track which employee took which action. Privileged access management (PAM) ensures only authorized people can access sensitive systems.
Every single one of these controls assumes a human being is the actor.
When an AI agent enters the picture, it does not log in the way an employee does. There is no ticketing system request. Instead, it operates across dozens of tools and data sources simultaneously, making hundreds of micro-decisions in the time it takes a human to read one email. Furthermore, because teams typically gave it broad permissions during setup to work efficiently, it often has access to far more than it actually needs for any single task.
This is what security built only for humans looks like when it meets AI: the agent operates under a user account or service account, inheriting whatever permissions that account holds. There is no granular control over what the agent can actually do versus what the account technically allows. Nobody built a system to monitor autonomous action at the speed AI operates.
If you have also not addressed issues like scattered knowledge across tools and teams, your AI agent may be accessing data from systems it never should have touched in the first place, simply because nobody ever tightened permissions to match task-specific needs.
Why Traditional Security Controls Fail AI Agents Specifically
Let’s be honest about the gap here. Traditional security controls fail AI agents for three concrete reasons.
First, there is no identity model for autonomous actors. Your security infrastructure knows how to handle Bob from finance. It does not know how to handle an AI agent that is simultaneously querying your CRM, drafting emails, updating records, and sending Slack messages, all without a human in the loop at any step. The agent lacks a distinct identity with its own purpose-built constraints.
Second, access is too broad by design. AI agents need access to function. In the rush to get them operational, teams frequently give agents overly permissive service accounts because it is faster than building granular controls. The result is an autonomous system with access to data and actions far beyond what its actual tasks require. Security researchers call this the principle of least privilege failure — and it is rampant in early AI deployments.
Third, traditional monitoring cannot keep pace with autonomous action. Your SIEM (Security Information and Event Management) system is excellent at flagging unusual human behavior. However, it cannot distinguish between an AI agent doing its job correctly and an AI agent doing something it should not. When agents operate at machine speed, by the time a human reviews the logs, the damage may already be done.
This connects directly to a point worth noting: if your organization is also running without a proper approval or review layer for AI decisions, you are compounding the risk substantially. Two missing layers — security and oversight — do not just add up. They multiply.
The Risks You Are Probably Not Thinking About
Most security conversations about AI agents focus on external threats: prompt injection attacks, adversarial inputs, data poisoning. Those are real and worth addressing. However, the more immediate risk for most organizations is internal and architectural.
When an AI agent inherits broad access and no behavioral guardrails, a few scenarios become dangerously plausible. For example, the agent accesses and transmits data to external tools or APIs it was configured to work with, but nobody reviewed whether those integrations were appropriate for the sensitivity of that data. In addition, the agent takes actions in connected systems based on decisions rooted in multiple conflicting versions of the same data, producing outputs that are technically authorized but factually wrong. Or the agent, following its instructions correctly, triggers a cascade of automated actions across systems that no human would have approved if they had been paying attention.
None of these scenarios require a hacker. They are entirely self-inflicted.
Consequently, there is also the compliance dimension to consider. In regulated industries — healthcare, finance, legal — every data access and every decision needs to be traceable and defensible. An AI agent operating through a general service account with no dedicated audit trail is an audit disaster waiting to happen.
Moreover, for organizations where undocumented workflows still live inside people’s heads, this risk is even higher. An AI agent cannot follow a process that was never formalized, and the resulting improvisations under insufficient security controls can expose data in ways nobody anticipated.
Industry Data: The Numbers That Should Concern You
The data on AI security failures is starting to come in, and it is not reassuring.
To begin with, according to IBM’s Cost of a Data Breach Report 2024, the average cost of a data breach reached $4.88 million, a 10% increase from 2023 and the highest figure IBM has recorded. IBM also found that organizations using AI extensively in security operations detected and contained breaches significantly faster, showing how modern security automation can reduce breach impact and response delays. Source: IBM Cost of a Data Breach Report 2024
Additionally, Gartner predicts that by 2028, 25% of enterprise GenAI applications will experience at least five minor security incidents per year, up from just 9% in 2025, as agentic AI adoption and immature security practices continue to expand the attack surface. Source: Gartner, April 2026
Perhaps most striking, a Cloud Security Alliance and Oasis Security survey found that 78% of organizations do not have documented and formally adopted policies for creating or removing AI identities — meaning most enterprises cannot even account for the non-human actors already operating inside their systems. Source: Cloud Security Alliance, January 2026
Taken together, these are not edge cases. They represent the mainstream trajectory of AI adoption without a matching evolution in security thinking.
Real-World Case Study: Samsung’s ChatGPT Data Leak
Company: Samsung Electronics
What happened: In early 2023, Samsung engineers began using ChatGPT to assist with internal code review and debugging tasks. Within weeks, three separate incidents of sensitive data leakage occurred. In one case, an employee submitted proprietary source code to ChatGPT for review. In other reported cases, employees shared internal meeting content and proprietary technical information with AI tools.
None of this was the result of malicious intent. It was the direct result of employees using an AI tool with no security guardrails, no defined boundaries around data sharing with external AI systems, and no access control layer between sensitive internal data and the AI processing it.
Key outcome: Samsung banned internal ChatGPT use shortly after and began developing its own internal AI tools with security controls built in. Samsung was concerned that sensitive data sent to external AI platforms would be difficult to retrieve or delete once uploaded, creating a long-term confidentiality risk with no reliable remediation path.
Why this matters for AI agents: Samsung’s engineers were using AI as a tool they manually interacted with. AI agents operate autonomously. If a manually operated AI tool caused this scale of exposure, an autonomous agent with broad data access and no behavioral guardrails represents a fundamentally larger risk profile.
Verified Sources: The Verge, “Samsung bans employee use of AI tools like ChatGPT after data leak” — theverge.com/2023/5/2/23707796/samsung-chatgpt-ban | AI Incident Database, Incident 768 — incidentdatabase.ai/cite/768
What an AI-Ready Security Model Actually Looks Like
Building security for AI agents is not about replacing your existing framework. Rather, it is about extending it to account for a new type of actor. Here is what that means in practice.
Dedicated identity for every AI agent. Each agent should have its own service identity with purpose-built permissions scoped only to what that agent needs for its specific tasks. Not a shared service account. Not a borrowed user account. Its own identity with its own access log.
Behavioral monitoring, not just access monitoring. You need systems that track what the agent actually does, not just whether it had permission to do it. Specifically, monitoring for anomalous sequences of actions, unusual data volumes, or patterns that deviate from the agent’s defined task scope are all critical.
Data classification and agent access tiers. Not every agent should have access to every data tier. As a result, you need explicit rules around what categories of data each agent can interact with, enforced at the infrastructure level, not just through configuration trust.
Defined operational boundaries. As we have explored in the context of real-time data access and AI agents, agents need to know what systems they are allowed to touch, in what sequence, and under what conditions. These are not just workflow guidelines. They are security boundaries.
Human escalation triggers. For high-stakes or sensitive actions, agents should be configured to pause and escalate to a human decision-maker rather than proceed autonomously. This is not a weakness in your AI strategy. In fact, it is a mature, defensible design choice.
Practical Steps to Start Closing the Gap
You do not need to rebuild your entire security architecture before deploying AI agents. However, you do need to move deliberately through a few foundational steps.
Start by auditing every AI agent’s current access permissions. Document what each agent can touch, what it actually touches during normal operation, and where those overlap. The difference between “can access” and “needs access” is where your immediate risk lives.
Next, establish a dedicated identity management practice for non-human actors. Many organizations already have frameworks for managing service accounts. Therefore, extend and formalize this for AI agents specifically, giving each agent its own identity and its own audit trail.
Then define and document what actions are in scope for each agent. This connects directly to the broader challenge of making your documentation reflect how work actually gets done. An agent operating against undocumented process boundaries is a security problem as much as an operational one.
Finally, integrate agent behavior monitoring into your existing SIEM or observability stack. That way, you have a single view of what your human and non-human actors are doing, with alerting configured for patterns that deviate from expected task behavior.
Conclusion
The organizations that get AI agents right over the next two years will not be the ones with the most powerful models. They will be the ones that built the right foundations before scaling.
Security built only for humans is not a small gap to patch. It is a structural mismatch between your risk environment and your risk controls. AI agents are already operating in enterprises that were never designed to contain them, and the incidents that result are increasing in both frequency and cost.
The good news is that the path forward is clear. Treat AI agents as distinct actors that need their own identity, their own access controls, and their own behavioral monitoring. Build boundaries that are enforced, not assumed. And do not confuse “no incident yet” with “no risk.”
If you are mapping out AI agent readiness for your organization, it helps to look at these issues together. From why scattered knowledge silently limits AI performance to the structural reasons real-time data access shapes AI agent reliability, security is one piece of a larger picture.
Ready to evaluate where your security model stands for AI agents?
Connect with the Ysquare Technology team on LinkedIn to start that conversation.
Read More
Ysquare Technology
22/05/2026







